In this project, I want to create a visual guide to better understand Git operations. While learning how to effectively work with Git, I realized that seeing what happens visually when running Git commands helps solidify the concepts.
Check out the following links:
- A fantastic tool for seeing Git commands in action with a visual representation: link
- A humorous and practical guide for fixing Git mistakes quickly and effectively: link
Working with Git locally
create first (and second) commit
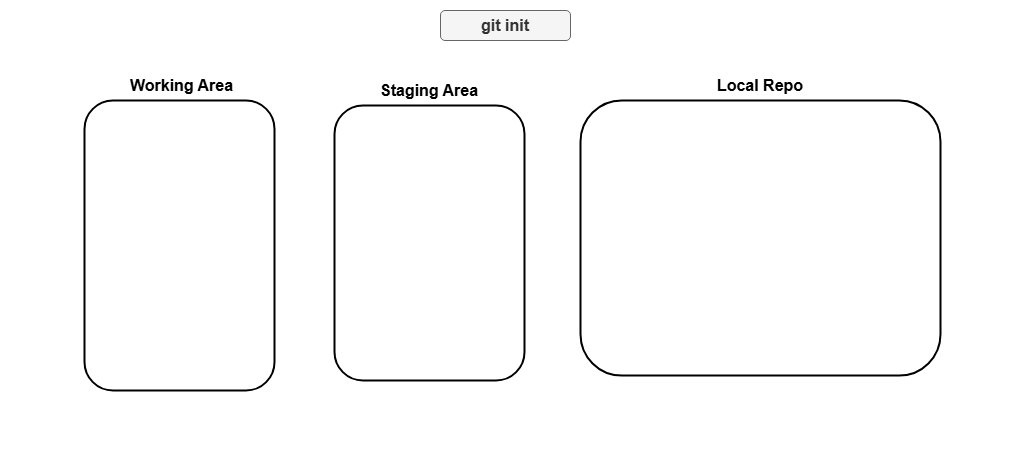
git init
Think of this as setting the stage. When you run git init in your project’s directory, you’re creating a new Git repository. This tells Git to start tracking changes in your files. It’s the first step in bringing your project under version control.
git init
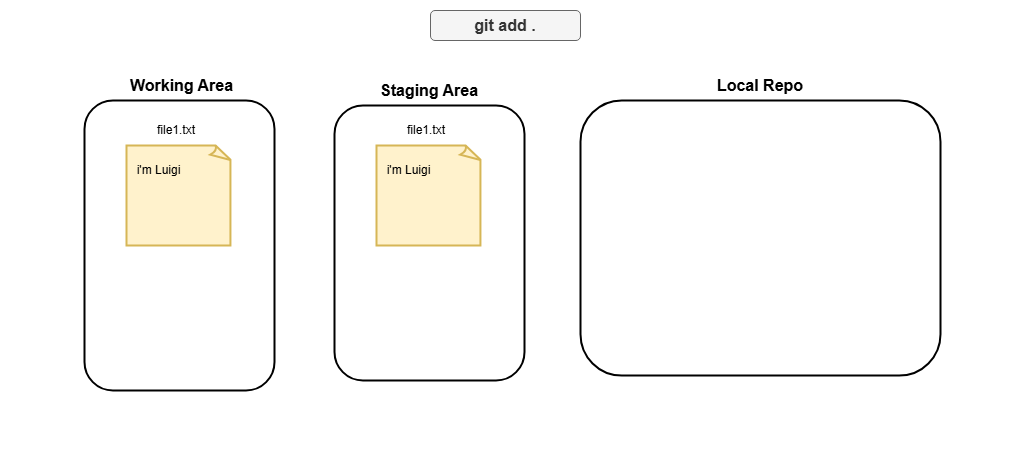
git add
Now that your repository is set up, it’s time to decide what changes you want to track.
The git add . command stages all changes in your current directory for the next commit.
Whether you’ve created new files, updated existing ones, or deleted something, this command ensures Git knows about it.
git add .
The . after git add means “track every file in the repository” (expect the one specified in .gitignore).
If you only want to track specific files or directorys, you can do:
git add /path/to/file
git add /path/to/dir/
git commit
Staging changes is great, but to make them permanent in Git’s history, you need to commit. The git commit command saves a snapshot of your staged changes. It also requires a message describing what you’ve done, like this:
git commit -m "first commit"
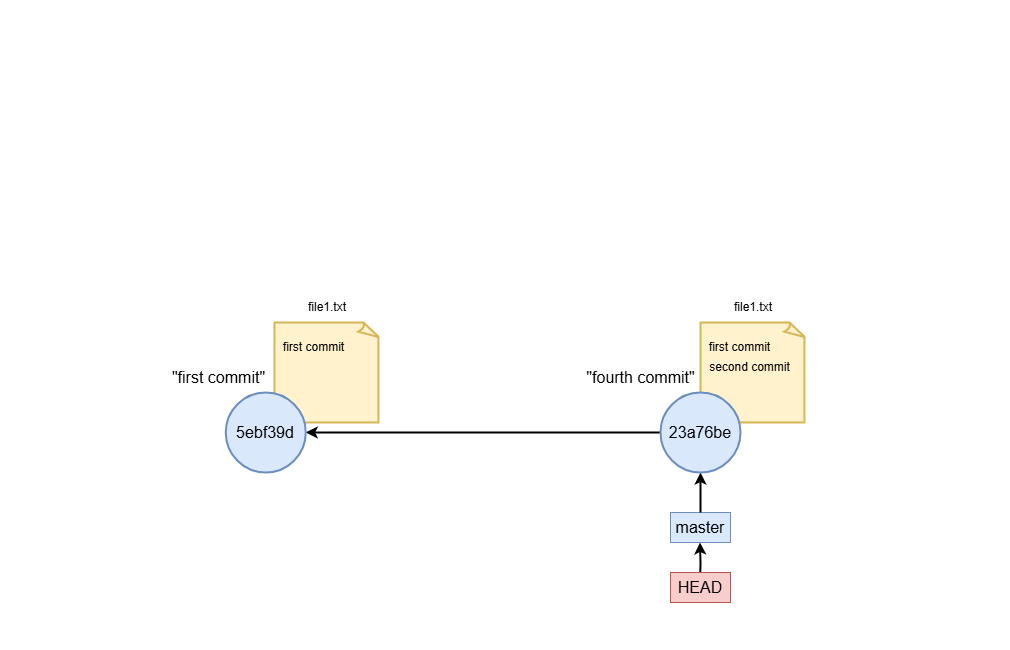
Example, create first and second commit
Below here an example on how to start a repository and what happens graphically:
git init # Initialize empty git repository
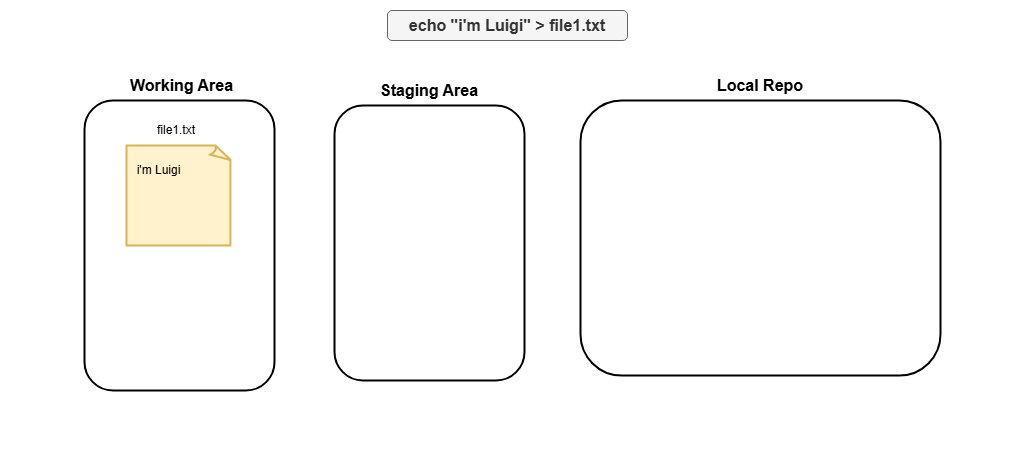
# First commit
echo "i'm Luigi" > file1.txt # Create first file
git add . # Stage content
git commit -m "first commit" # Create first commit
# Second commit
echo "ciao!" >> file1.txt
git add .
git commit -m "second commit"

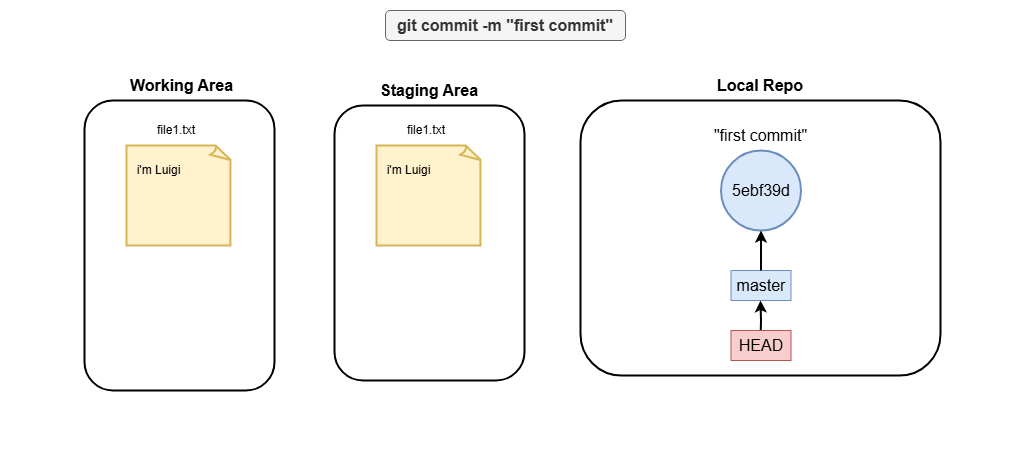
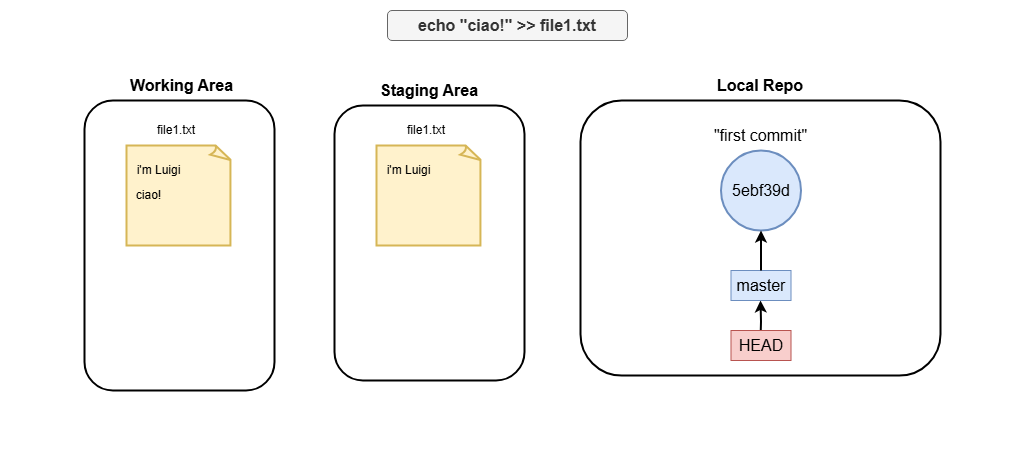
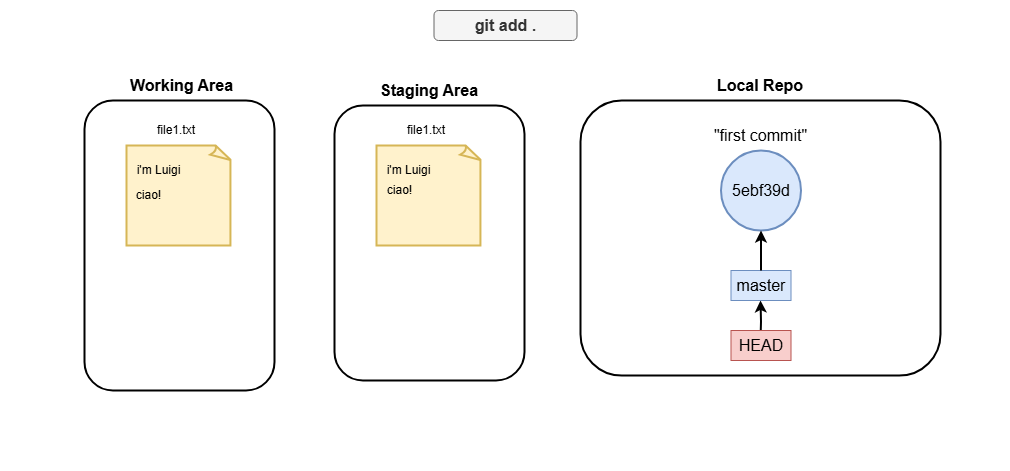
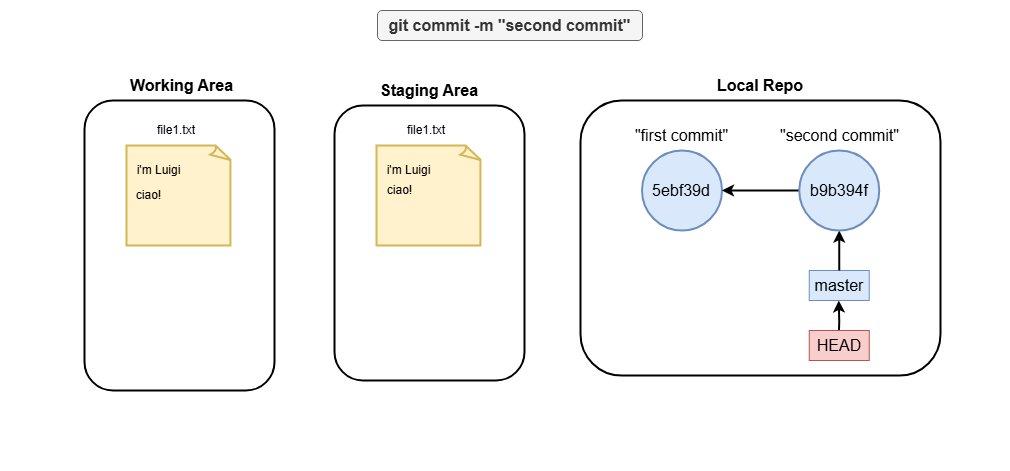
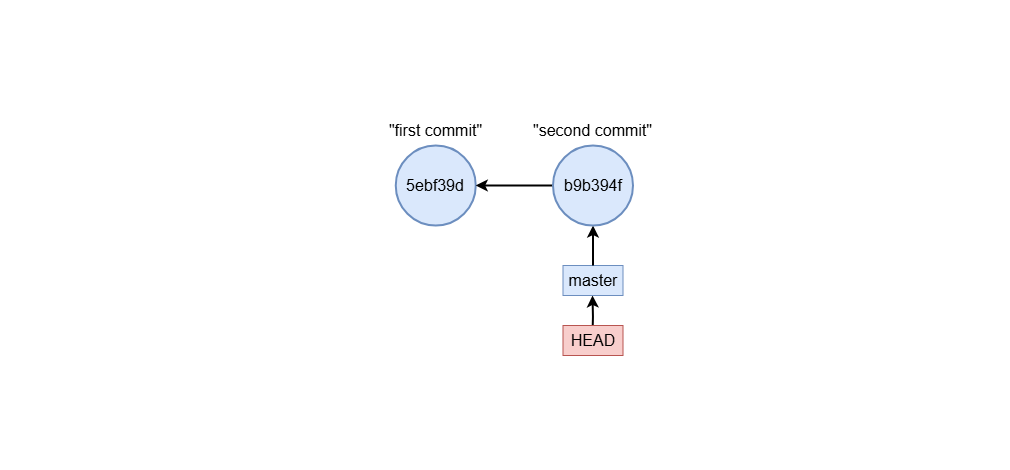
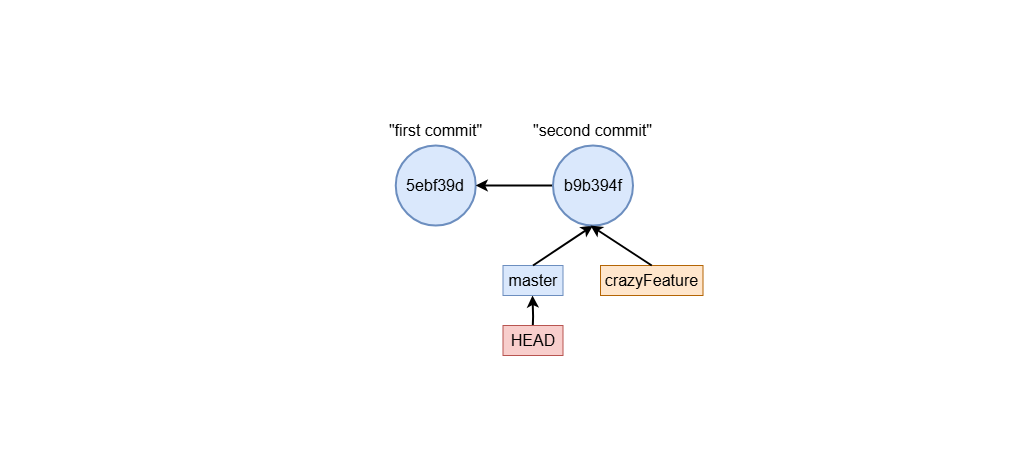
What is master and HEAD
Master and HEAD are both references. In the example above, HEAD reference always points to master branch reference. You can run:
$ cat .git/HEAD
ref: refs/heads/master
Where you see that HEAD points to master branch reference. In the other hand, the master reference points to the most recent commit sha.
$ cat .git/refs/heads/master
b9b394fb13ea56880d3d49b5a87bc8a19cdb8ab2
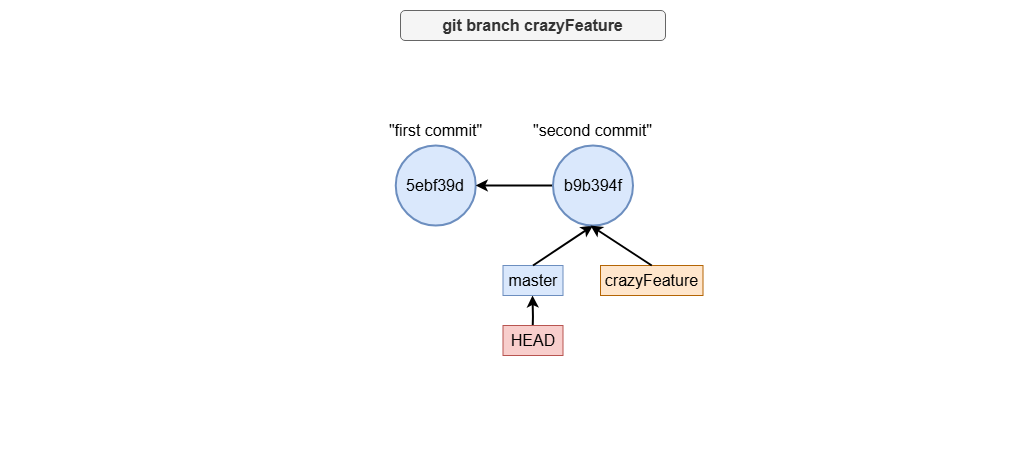
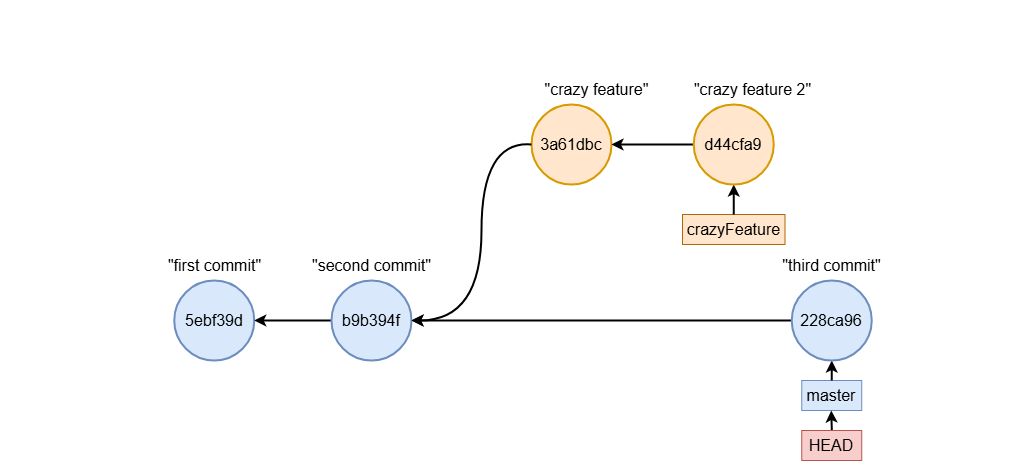
git branch - create (and delete) branches
git branch crazyFeature
This command creates a branch named crazyFeature at the current commit, but it doesn’t switch you to the new branch immediately. Instead, it simply adds a new pointer to your branch history.
Graphically, it can be seen as follows:
To delete a branch ref, simply type:
git branch -d crazyFeature
git log
git log
To make the output more compact and visually appealing, you can use the following options:
--oneline: Displays each commit in a single line, making it easier to scan.--all: Includes all branches, not just the one your HEAD is pointing to.--graph: Displays the history in a graphical representation, showing branch relationships.--date-order: By default the ordering of commits is topological (--topo-order), to have a chronologically ordered output you have to add the--date-orderflag.
git log --oneline --all --graph --date-order
Example:
* abc123 (HEAD -> master) Merge branch 'crazyFeature'
|\
| * xyz789 Added crazy feature
| * def456 Initial commit on crazyFeature branch
* 456def Third commit
* 123abc Second commit
* 789xyz Initial commit
This view helps you understand the branching and merging structure at a glance.
git status
- Which changes are staged for commit.
- Which changes are not staged yet.
- Any untracked files in your directory.
git status
git diff
Common Use Cases
- View Changes in Your Working Directory: To see changes between your working directory and the last committed state:
git diff
- Check Changes in a Specific File: If you want to focus on the changes in a particular file, specify its path:
git diff path/to/file
- Compare Two Commits: To view the differences between two commits, provide their commit hashes:
git diff commit1-sha commit2-sha
git checkout - moving HEAD around
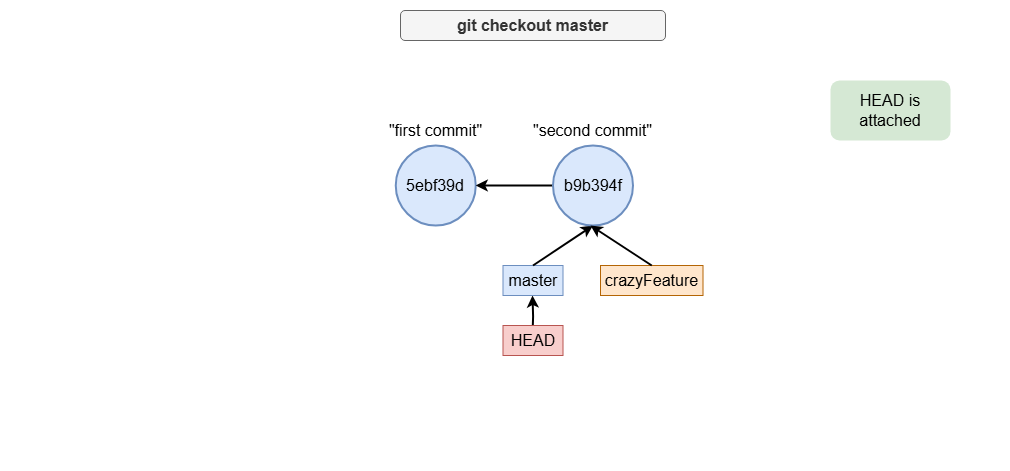
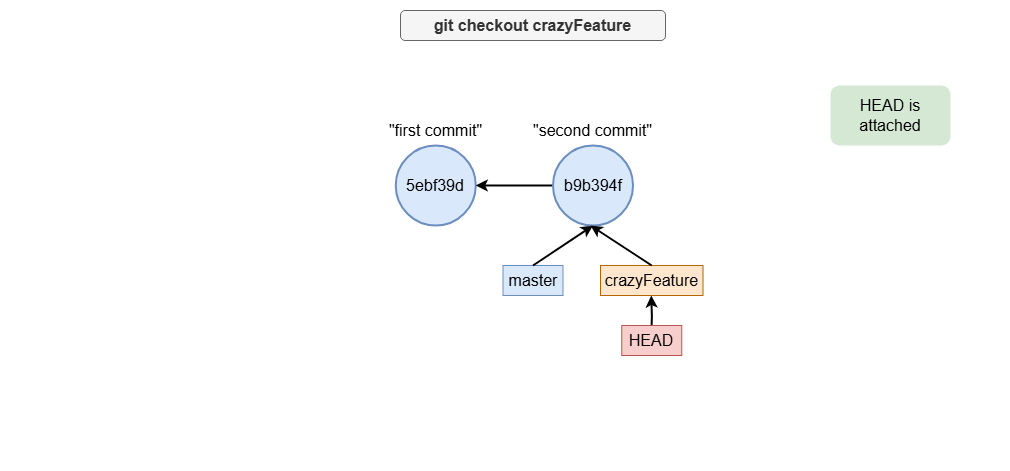
Moving HEAD to a Branch
When you switch to a branch using git checkout <branch-name>, HEAD is said to be “attached” to that branch.
This means any new commits will be added to the branch.
git checkout crazyFeature # Move HEAD to crazyFeature branch
git checkout master # Move HEAD to master branch
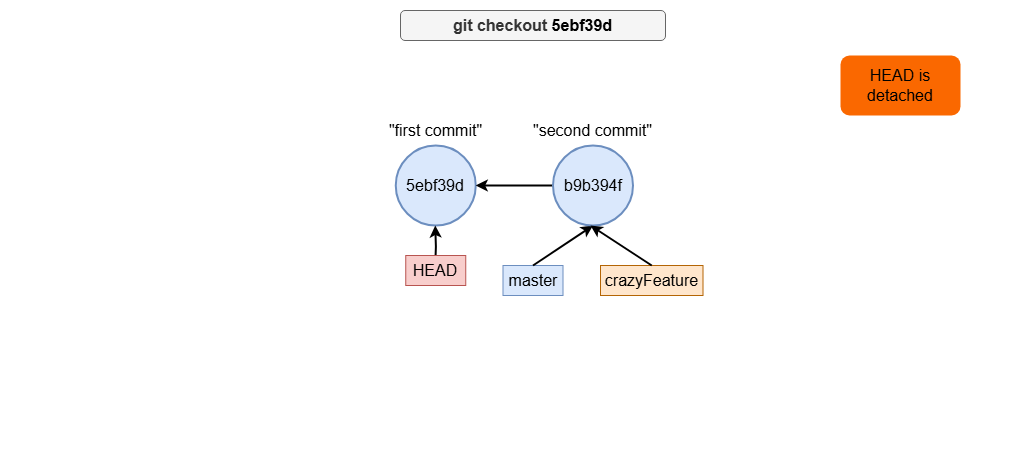
Detached HEAD state
If you check out a specific commit (e.g., by its hash), the HEAD enters a “detached” state. In this state, you can view the repository at that commit, but any changes or commits you make won’t belong to a branch.
git checkout a678ecf # Detach HEAD and view a specific commit
Detached HEAD can be useful for exploring past commits or testing code from a specific point in time, but be cautious: any commits made in this state may be lost unless explicitly saved (e.g., by creating a branch).
Visual feedback
Let’s see how the following commands can be visualized:
git checkout crazyFeature # Move HEAD to crazyFeature branch
git checkout master # Move HEAD to master branch
git checkout a678ecf # Detaching HEAD
Other ways to navigate history

develop branch
Switching to the Branch to Develop
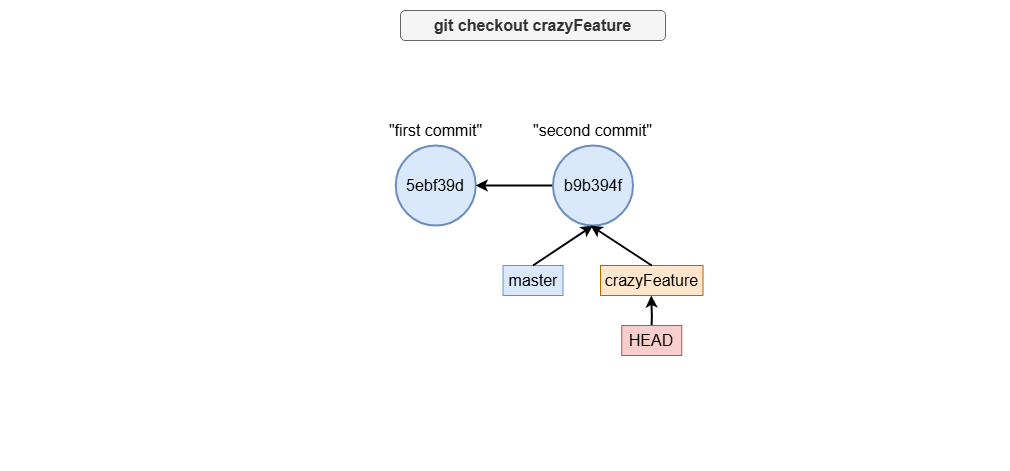
To start working on a branch, you use the git checkout (or git switch) command to move the HEAD pointer to the branch you want to develop. For example:
git checkout crazyFeature # Move HEAD pointer to the crazyFeature branch
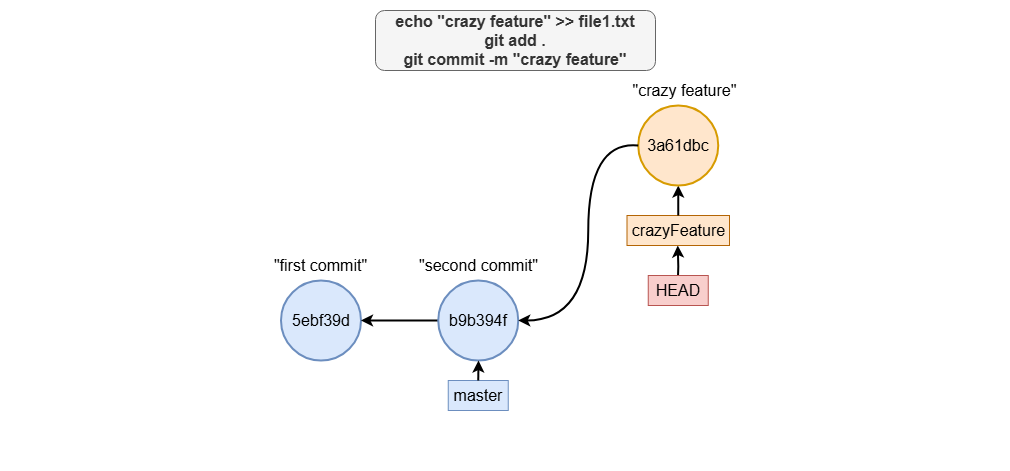
Making Commits on the Branch
Once you’re on the desired branch, you can start making changes, staging them, and committing. For example:
echo "crazy feature" >> file1.txt
git add .
git commit -m "crazy feature"
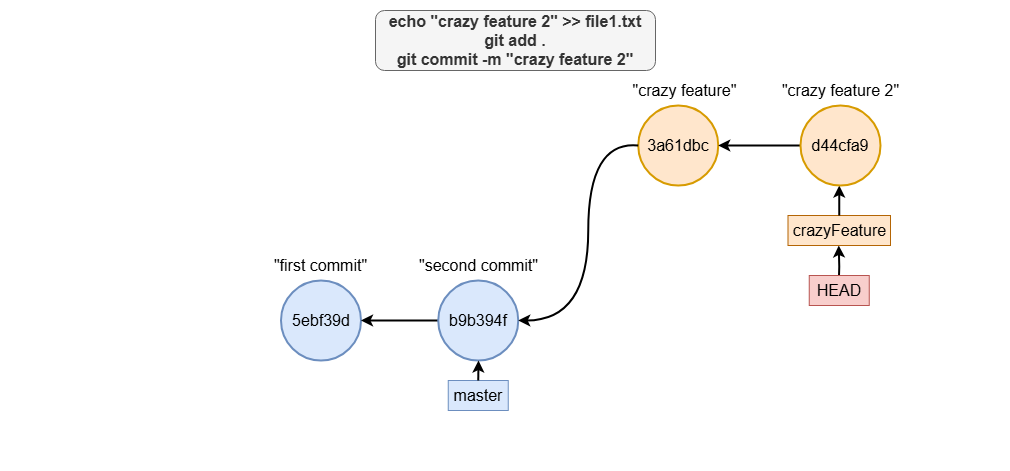
echo "crazy feature 2" >> file1.txt
git add .
git commit -m "crazy feature 2"
These commands add two commits to the crazyFeature branch, each capturing a new set of changes.
Switching Back to the Main Branch
If you want to shift your focus back to the main branch (e.g., master) to make changes there, simply switch branches again:
git checkout master # Move HEAD pointer back to master
You can then continue committing to the master branch:
echo "third commit" >> file1.txt
git add .
git commit -m "third commit"
Visualizing Changes
Switching branches dynamically updates your working directory to reflect the state of the branch you’re on. This ensures that your changes are isolated to the correct branch, keeping your work organized.
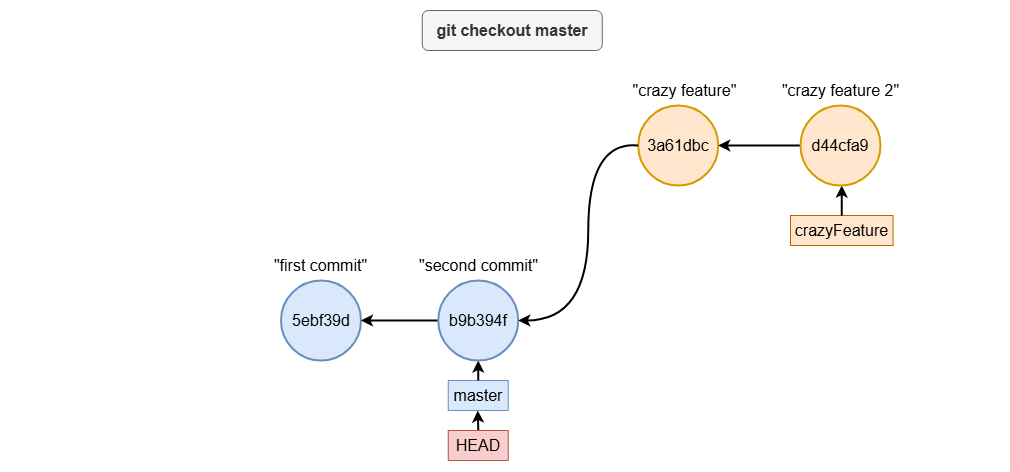
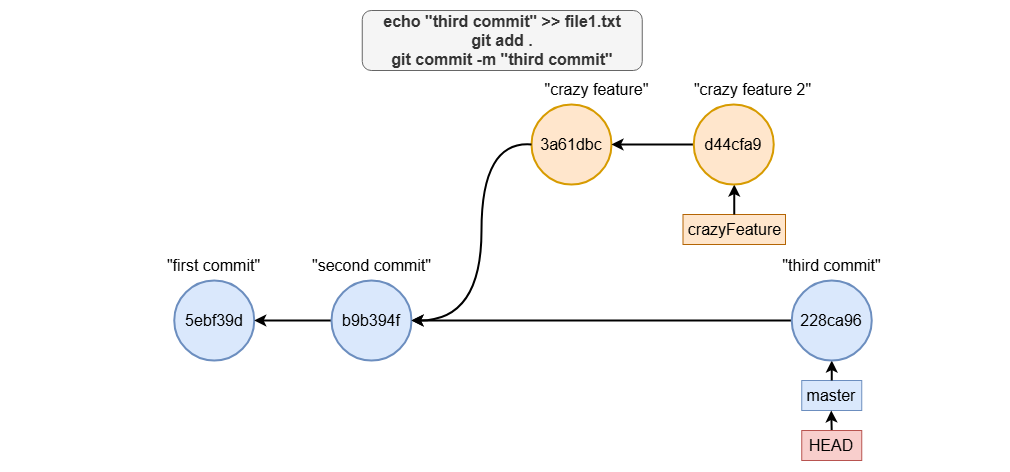
git reset - move branch reference around
Moving the branch tip
To reset the branch to a specific commit, use:
git reset 7ffe2cf
And this is a visualization of what happens:
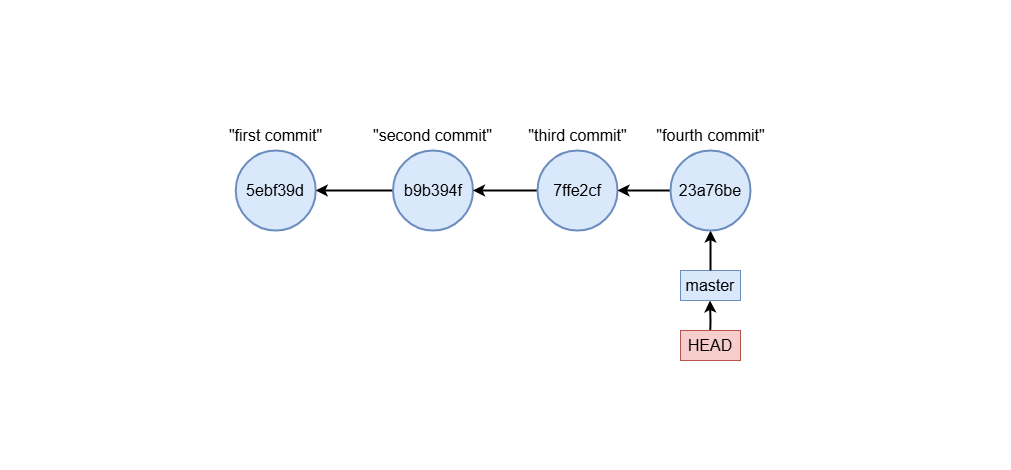
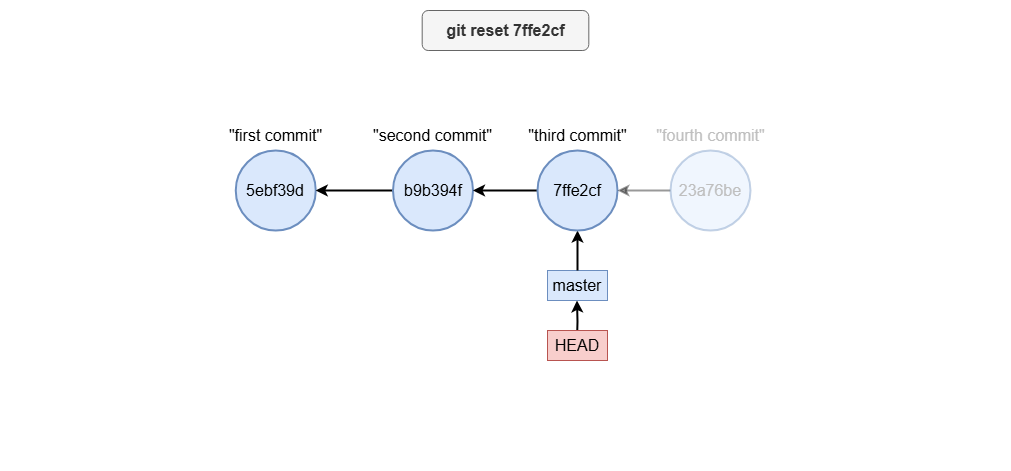
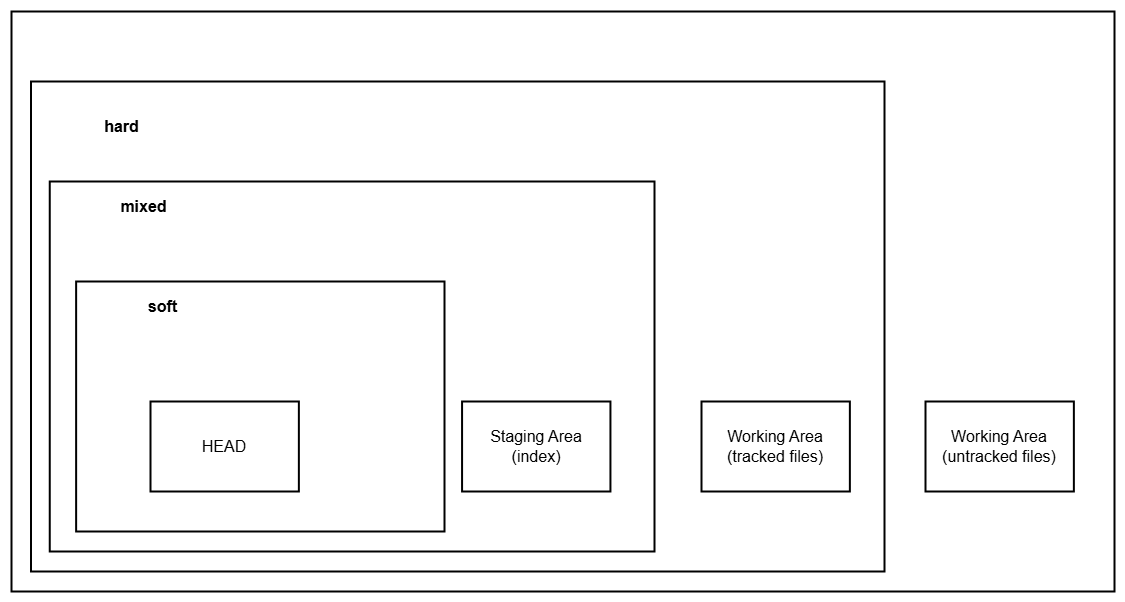
Git reset options
The git reset command has three primary modes to control what happens to your working directory and staging area.
- hard
A hard reset (--hard) changes the branch tip, staging area, and working directory to match the specified commit.
All uncommitted changes are lost.
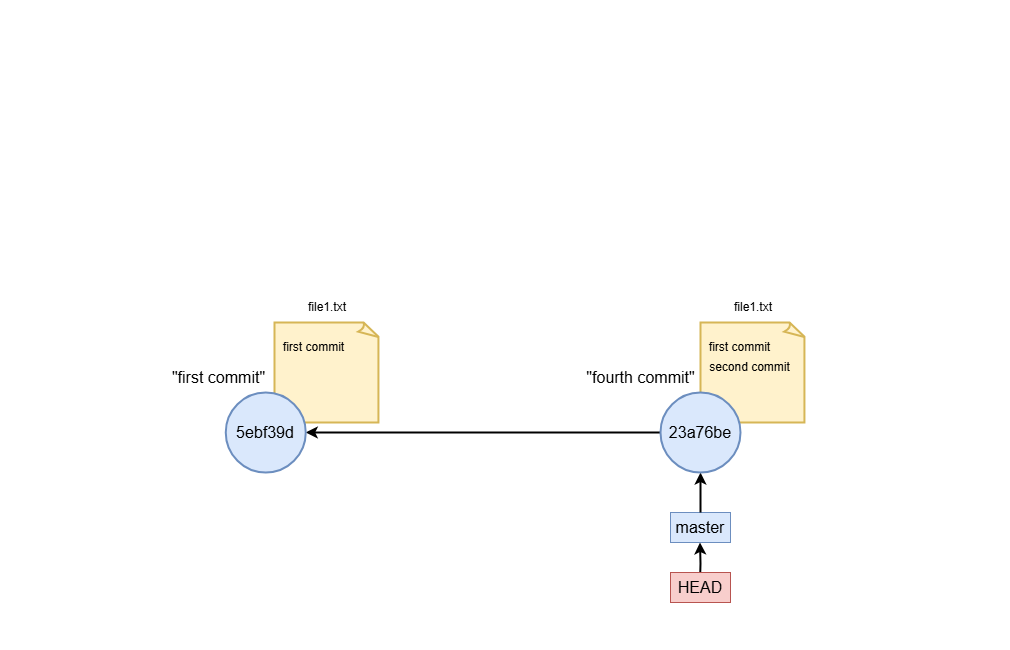
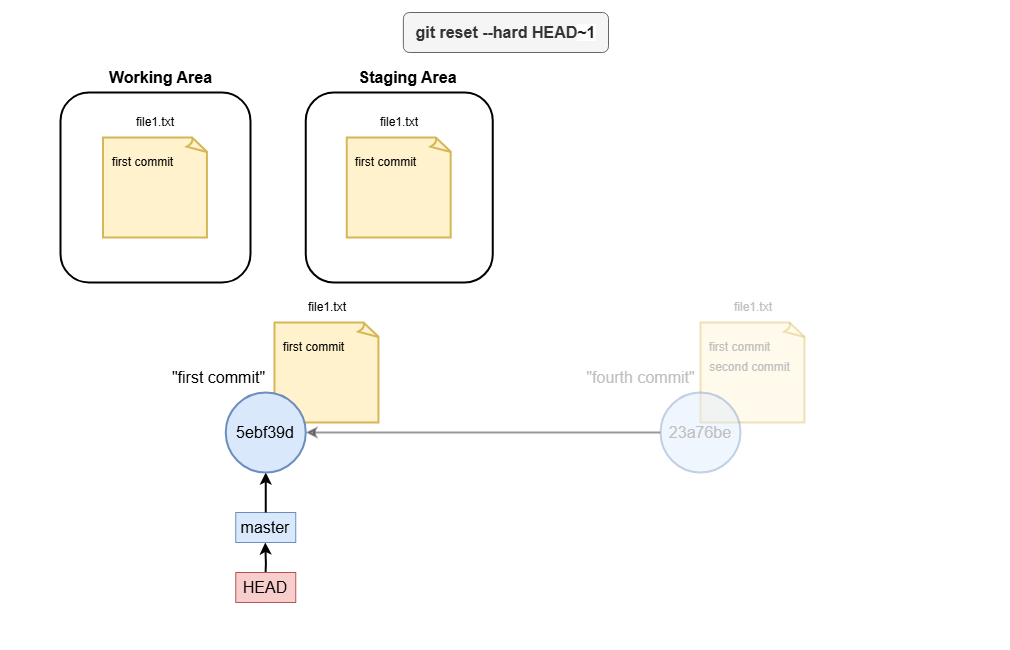
Use case: If you made a bunch of changes to the repo (not yet staged), but wan to revert to initial state, you can do.
git reset --hard HEAD
Note that any untracked file will still be kept (git does not know about untracked files).
To also remove untracked files (which you can view running git status) you can use the git clean command.
Use git clean -d to also recurse into directorys, or git clean -i for an interactive mode.
In any way, git clean is just a “fancy” bash rm.
- mixed
A mixed reset (--mixed) changes the branch tip and un-stages changes, but your working directory remains untouched.
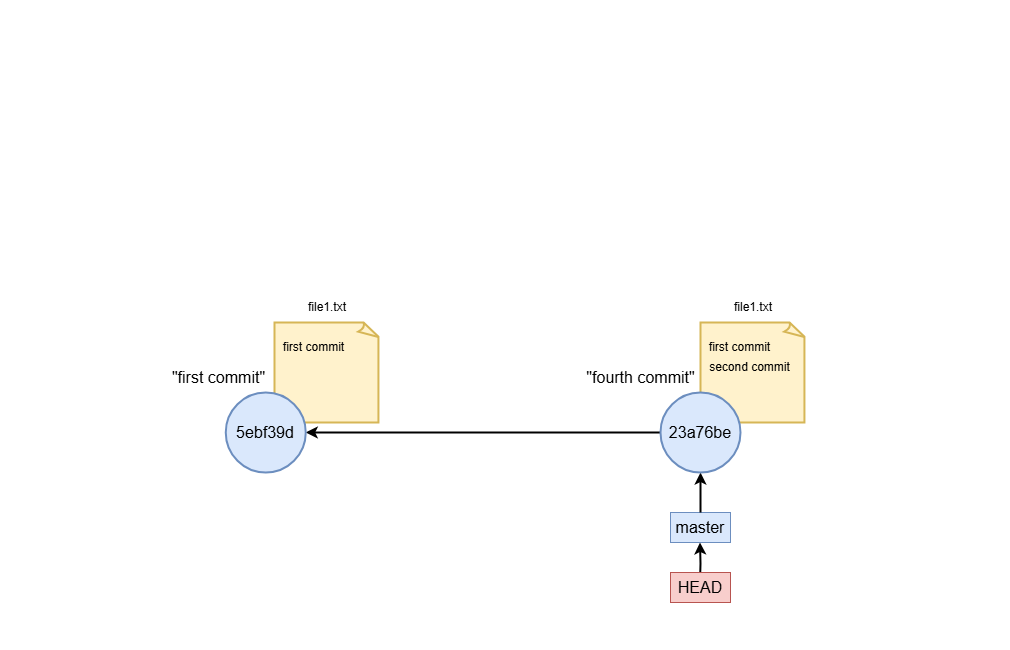
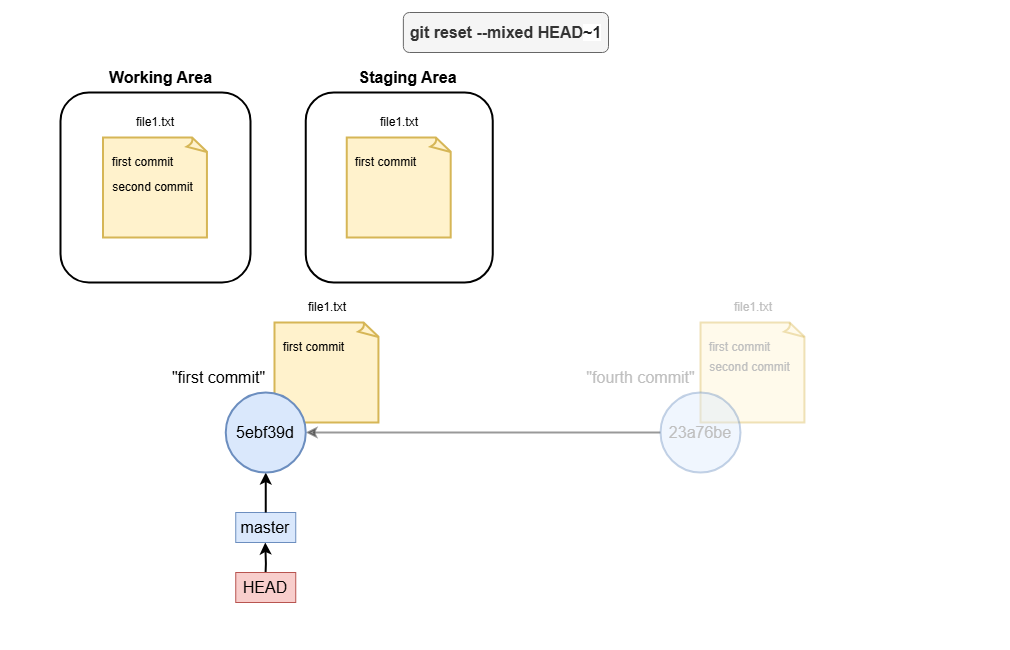
Use case: If you want to split last commit into multiple commits, you can do
git reset --mixed HEAD~
This will keep your file in the working area and now you can stage only the one you want and make more than one commit.
- soft
A soft reset (--soft) moves the branch tip but leaves both your working directory and staging area unchanged.
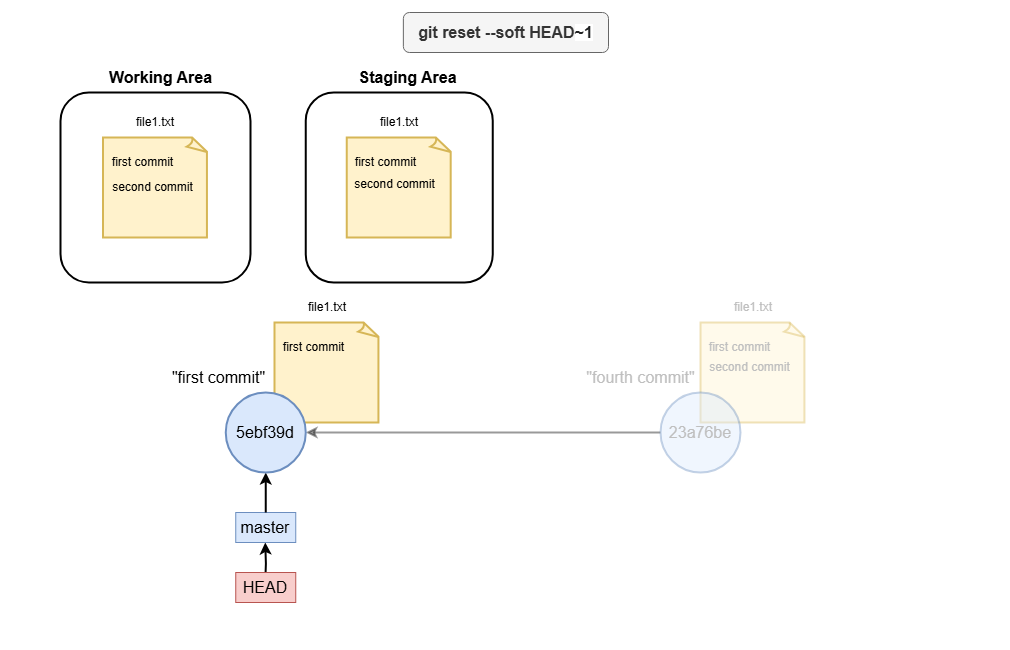
Resetting individual files
If you want to revert changes in a single file rather than resetting the entire branch, you can use:
git reset -- file.txt
Here, -- tells Git not to interpret subsequent arguments as commands.
Diagram for git reset
This diagram highlights how each mode affects the branch tip, staging area, and working directory. Using git reset effectively can help you rewrite history, clean up your work, and undo mistakes with precision.
git merge
Merging Two Branches
For example, to merge the crazyFeature branch into master, you can follow these steps:
git checkout master # Ensure you are on the branch to receive the changes
git merge crazyFeature
Visually, this is what happens:
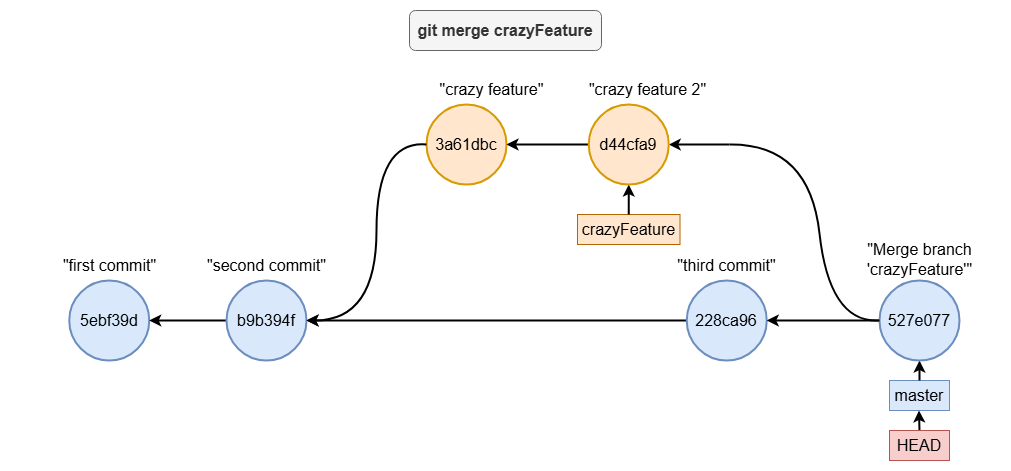
Handling Merge Conflicts
Sometimes, Git may encounter conflicts during the merge process if changes in the two branches overlap. In such cases, Git will pause the merge and mark the conflicting areas in your files.
Here’s an example of what a conflict might look like in file.txt:
first commit
second commit
<<<<<<< HEAD
third commit
=======
crazy feature
crazy feature 2
>>>>>>> crazyFeature
The «««< HEAD section shows the content from the current branch (master), while the ======= and »»»> crazyFeature sections show the conflicting changes from the branch being merged (crazyFeature).
Resolving the Conflict
To resolve the conflict, you can manually edit the file to decide which changes to keep, discard, or combine. For example, you might resolve the conflict like this:
first commit
second commit
third commit
crazy feature
crazy feature 2
After resolving the conflict, you need to stage the file and complete the merge:
git add .
git commit
This creates a new merge commit that records the resolution and finalizes the merge process.
rebase
When you rebase, Git reapplies commits from the current branch onto the target branch, one by one, as if they were made on top of it.
How Rebase Works
Let’s say you have two branches: master and crazyFeature. If you’ve made commits on crazyFeature and want to integrate those changes into master but avoid a merge commit, you can rebase:
git checkout master
git rebase crazyFeature

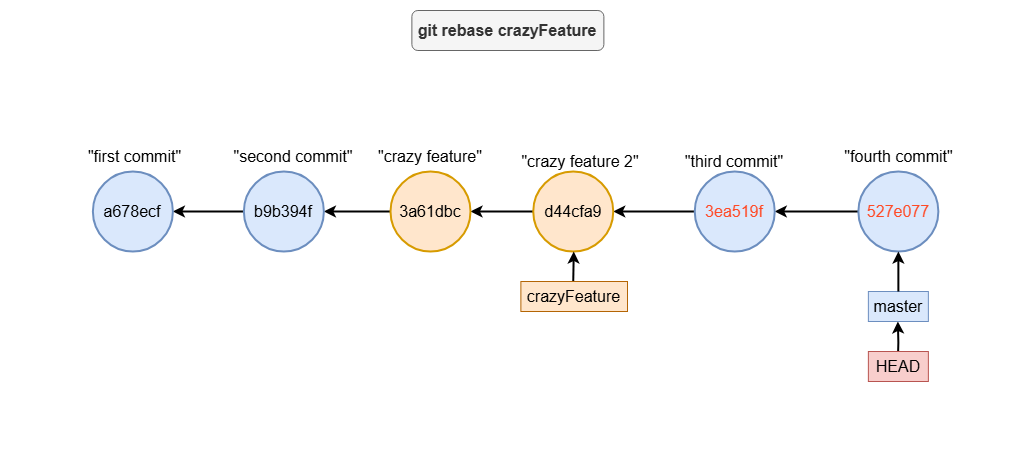
Key Points to Remember
- Use Rebase for Local Branches: Rewriting commit history with git rebase is safe only on branches that haven’t been shared with others. Avoid rebasing shared branches as it can lead to confusion.
- Resolving Conflicts: If there are conflicts during the rebase, Git pauses the process and asks you to resolve them. Once resolved, you can continue the rebase:
git rebase --continue
- Aborting a Rebase: If something goes wrong or you change your mind, you can abort the rebase and return to the original branch state:
git rebase --abort
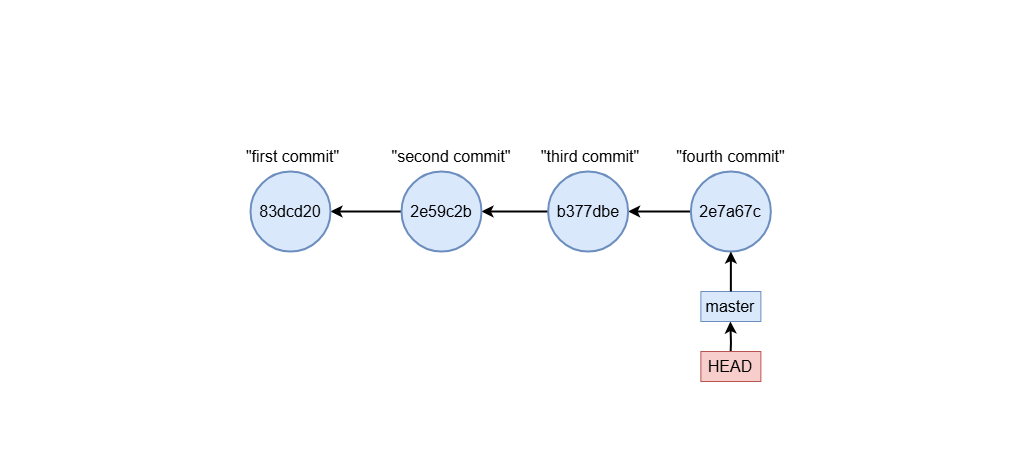
rebase interactive
Starting an Interactive Rebase
To begin an interactive rebase, specify the number of commits to include, or a base commit to rebase onto:
git rebase -i HEAD~3
This opens an editor displaying the commits in reverse chronological order:
pick 123abc Commit message 1
pick 456def Commit message 2
pick 789ghi Commit message 3
Each commit line starts with an action (pick) and is followed by the commit hash and message.
Actions in Interactive Rebase
- Reword: Edit the commit message without changing the commit itself.
- Squash: Combine multiple commits into one.
- Edit: Modify the content of a commit.
- Drop: Remove a commit entirely.
- Reorder: Change the sequence of commits.
Reword example
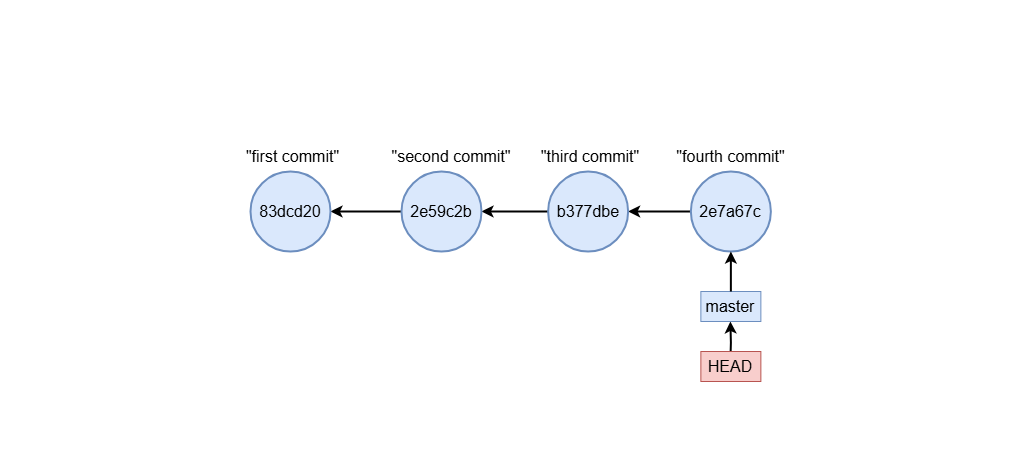
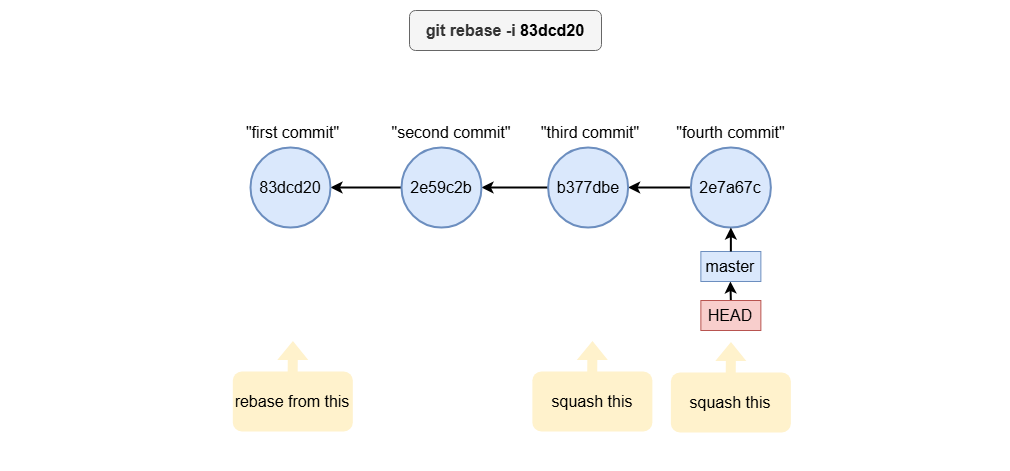
git rebase -i 83dcd20
To edit a commit message, change pick to reword:
reword 2e59c3b second commit
pick b377dbe third commit
pick 2e7a67c fourth commit
When you save and exit, Git will prompt you to enter a new message for the specified commit.
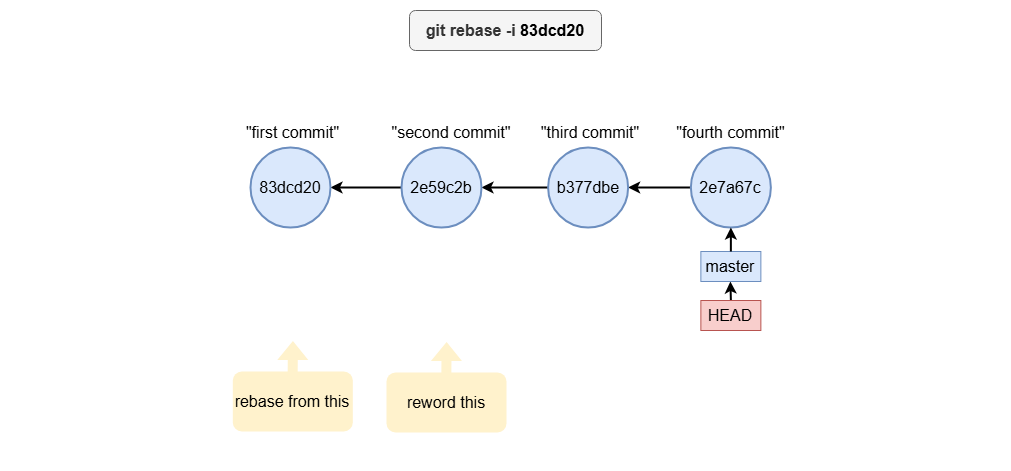
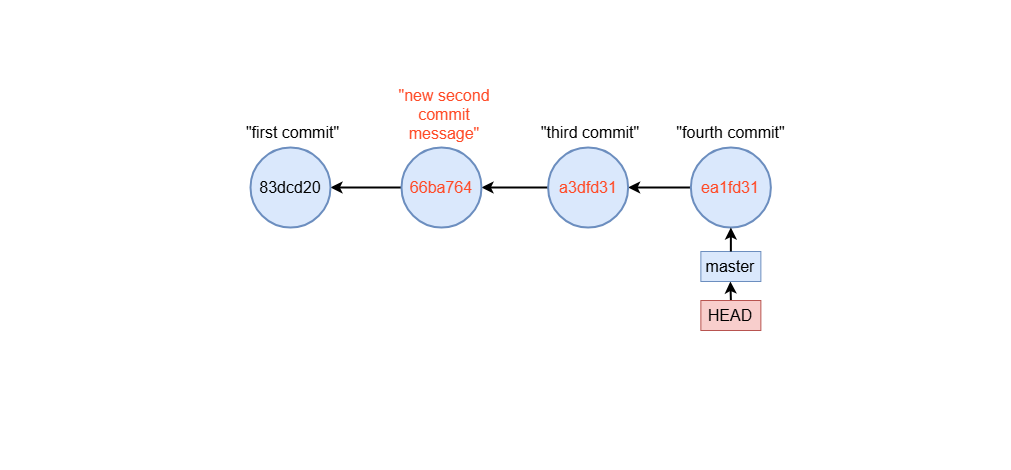
Squash example
Squashing combines multiple commits into one. To squash a commit, replace pick with squash (or s) for the commits you want to merge:
pick 2e59c3b second commit
squash b377dbe third commit
squash 2e7a67c fourth commit
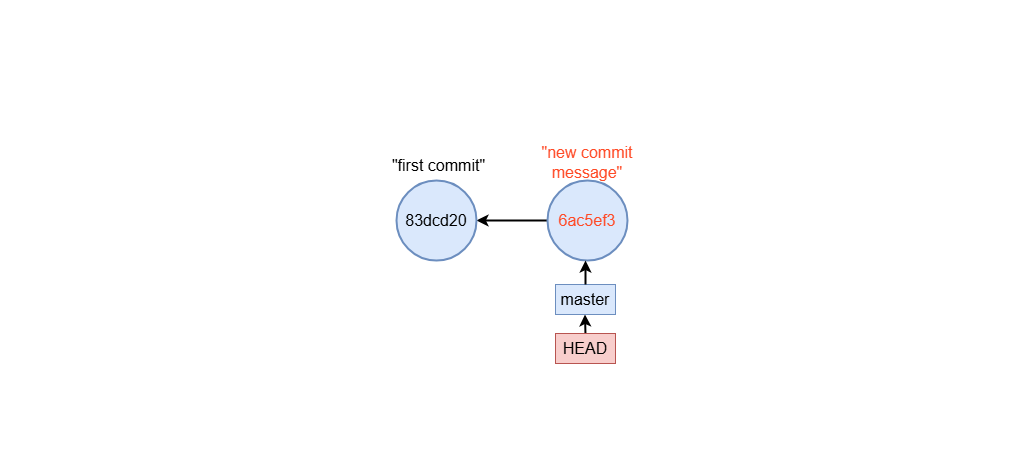
When you save, Git opens another editor to let you combine the commit messages.
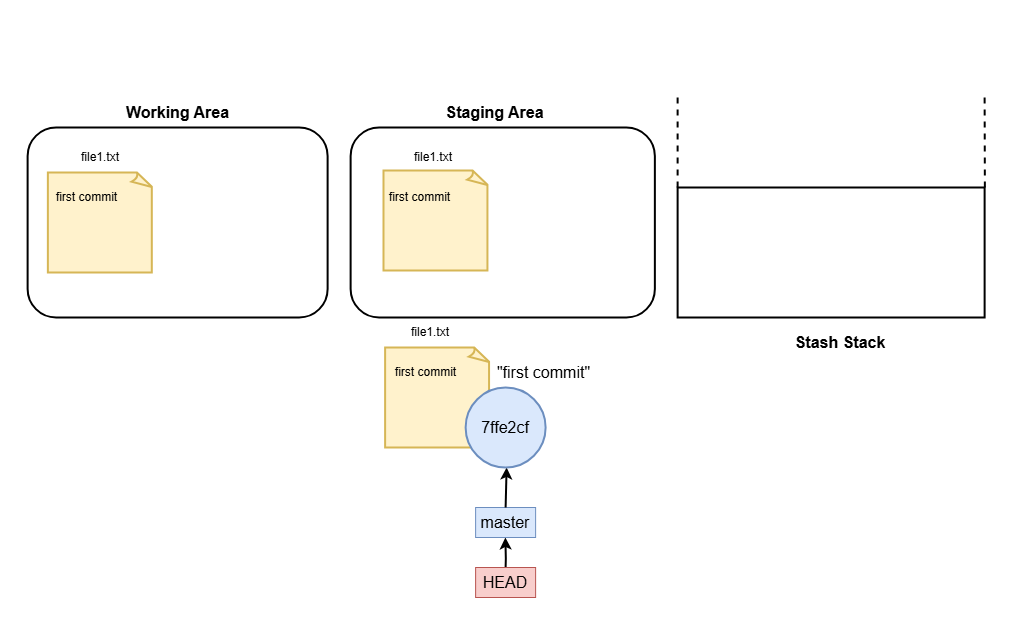
stash
How Git Stash Works
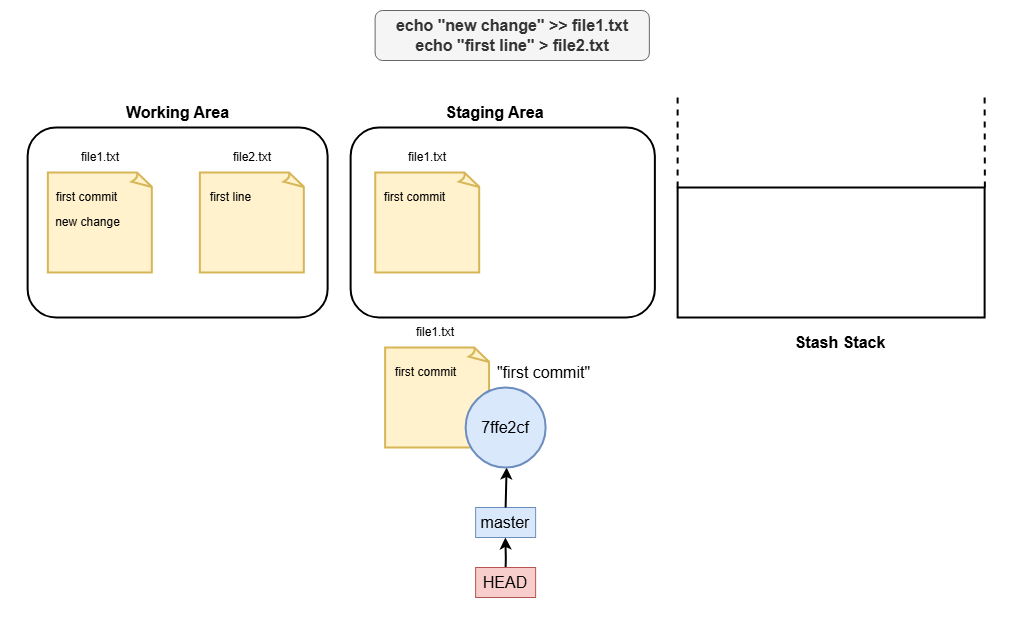
When you run:
git stash
Git saves the changes in your working directory (tracked) and staging area to a “stash stack.” This clears your working directory, allowing you to start fresh or switch branches without interference.
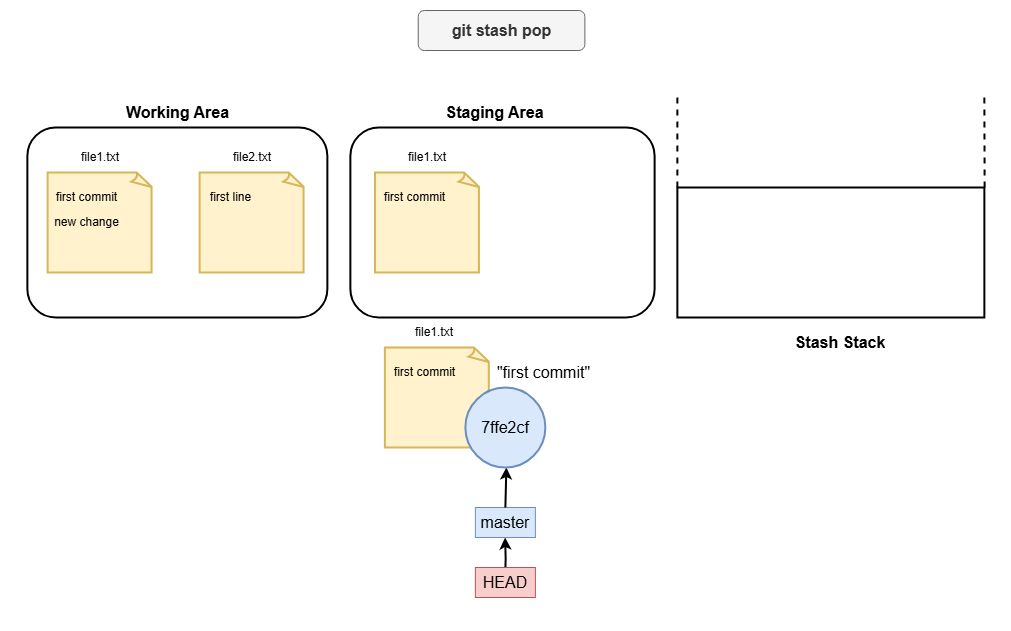
To retrieve your changes later, you use:
git stash pop
This restores the stashed changes and removes them from the stash stack.

Additional Stash Commands
- List Stashed Changes: View all saved stashes. To retrieve your changes later, you use:
git stash list
- Apply Stash Without Deleting: Retrieve changes without removing them from the stash stack.
git stash apply
- Clear Stash Stack: Remove all stashed entries.
git stash clear
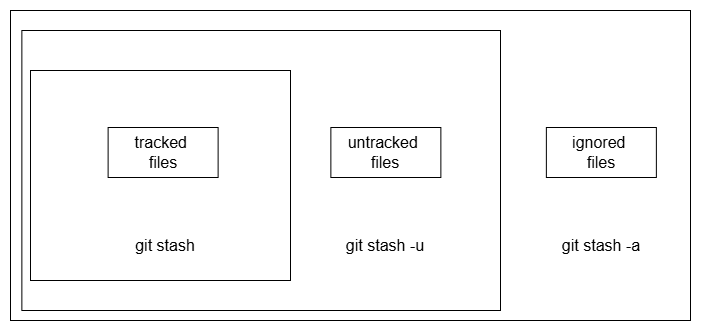
- Include untracked files in the stack: By default is only tracked files (the only git knows about):
git stash -u
Working with Git remotely
commit & push
Committing Changes Locally
The first step is to save your changes to the local repository with git commit. For example:
git add .
git commit -m "second commit"
This records the changes in your local repository. At this stage, the changes are not yet shared with others or pushed to the remote repository.
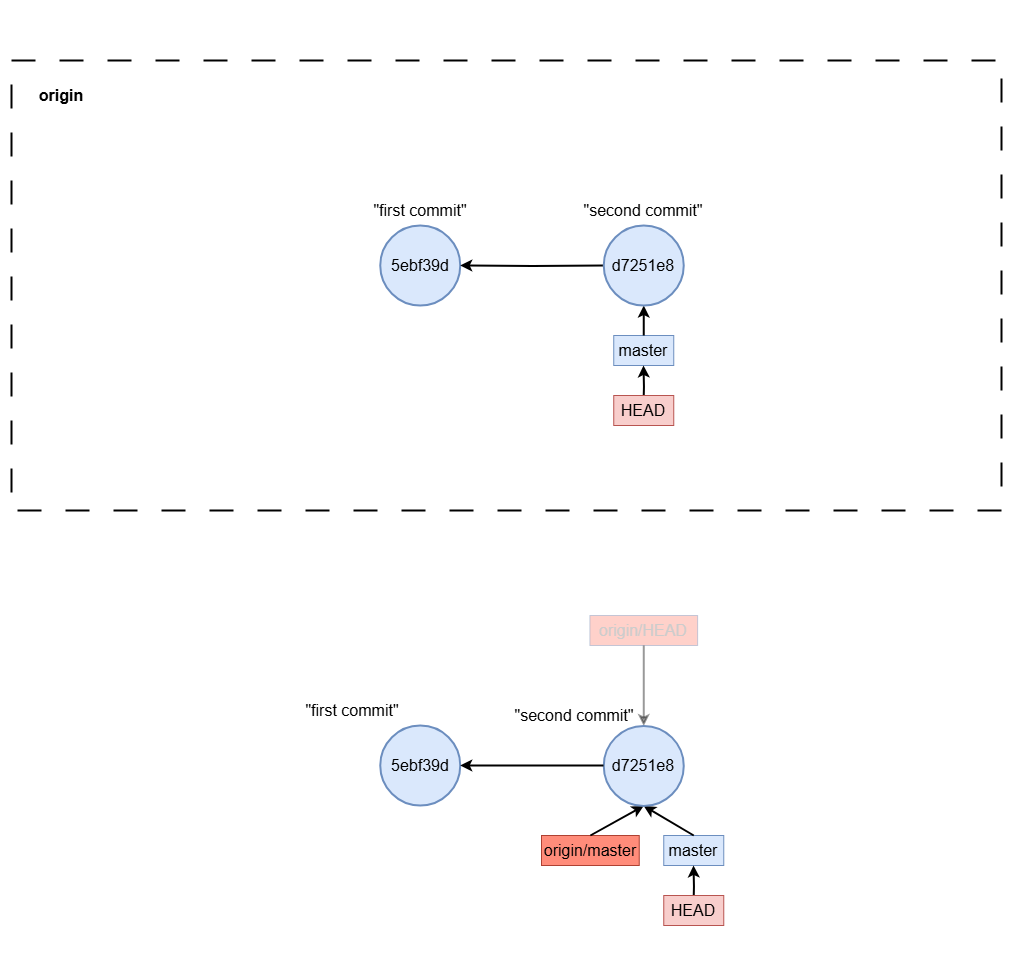
Pushing to a Remote Repository
To share your changes, you push them to a remote repository, such as origin, typically on a platform like GitHub or GitLab.
git push origin master
This command sends the commits from your local master branch to the master branch in the remote repository called origin.
Visualizing the Push Process
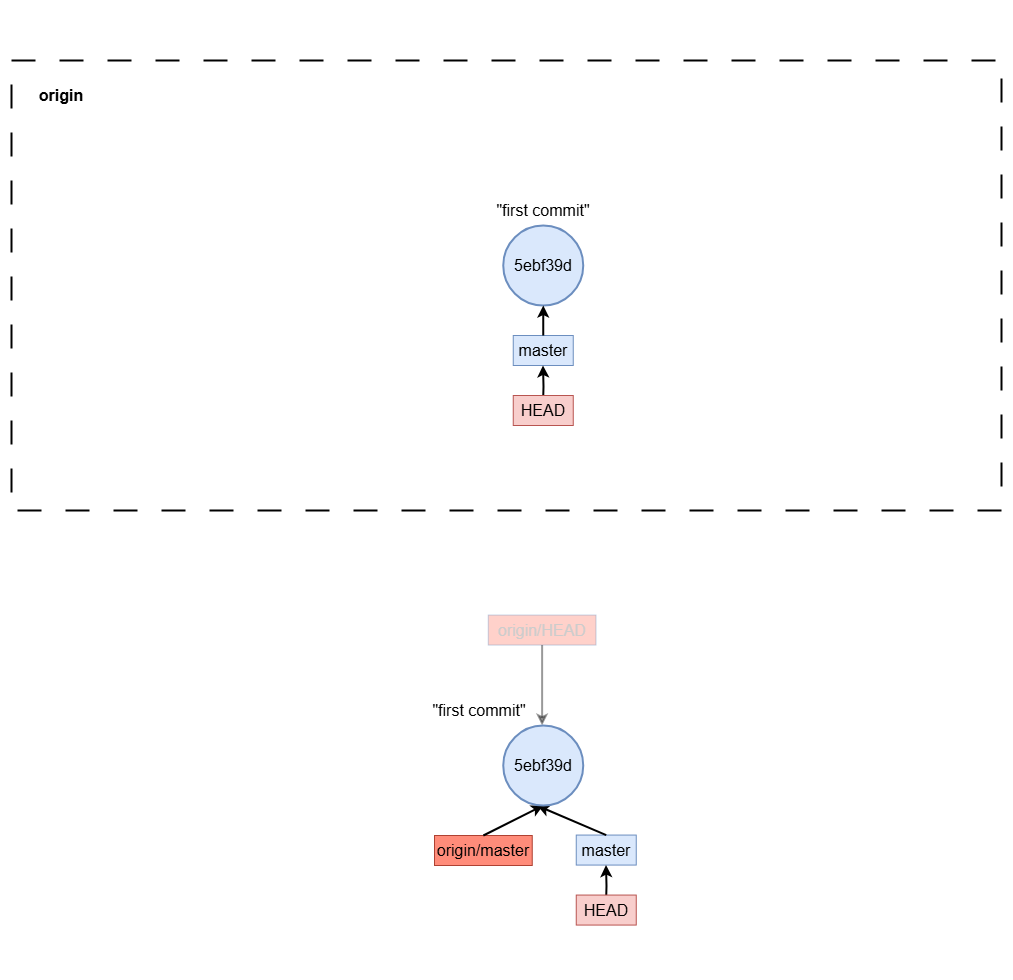

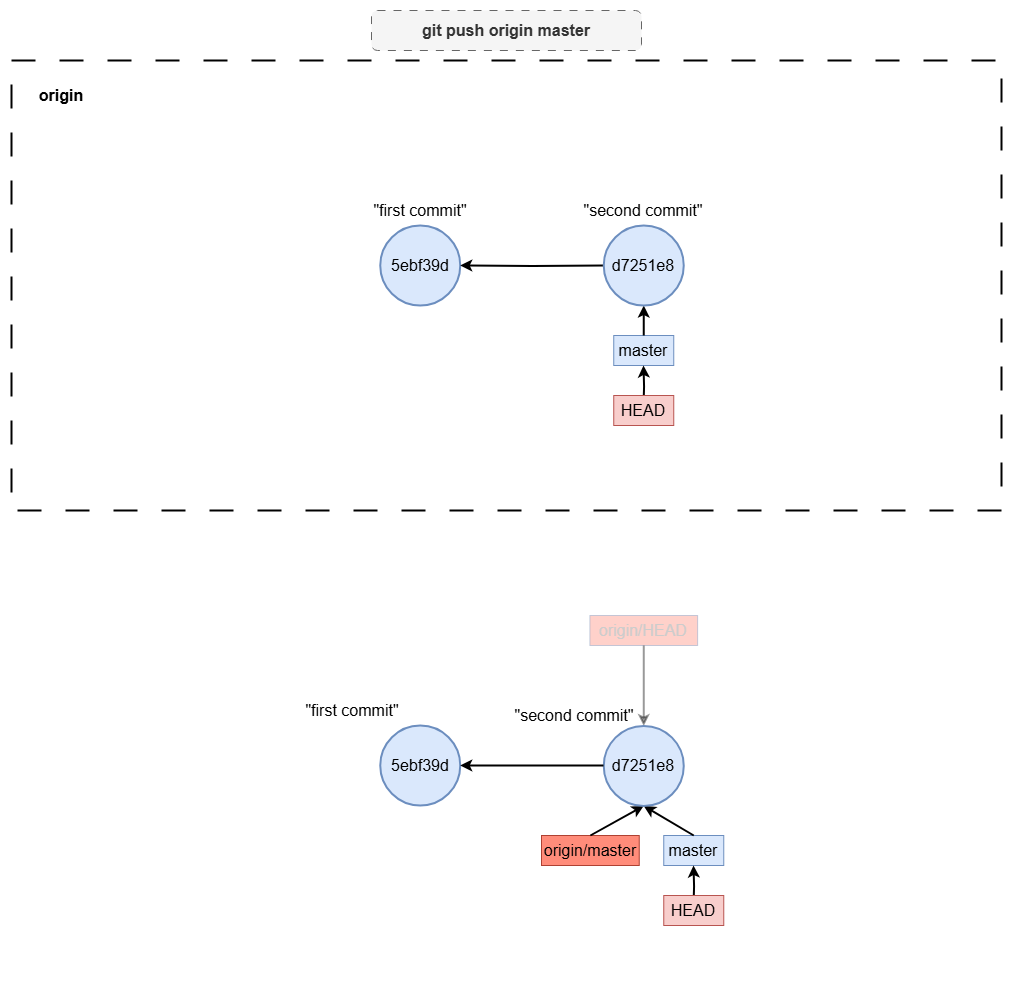
When you push to origin master, Git:
- Updates the remote branch to include your latest commits.
- Synchronizes your local repository with the remote, ensuring your changes are visible to others who pull from the remote branch.
working with branches
Pushing a Local Branch to the Remote
To share a branch with others, you can push it to the remote repository using:
git push origin crazyFeature
This command creates a new branch in the remote repository (if it doesn’t already exist) and pushes the commits from your local crazyFeature branch to the remote crazyFeature branch.
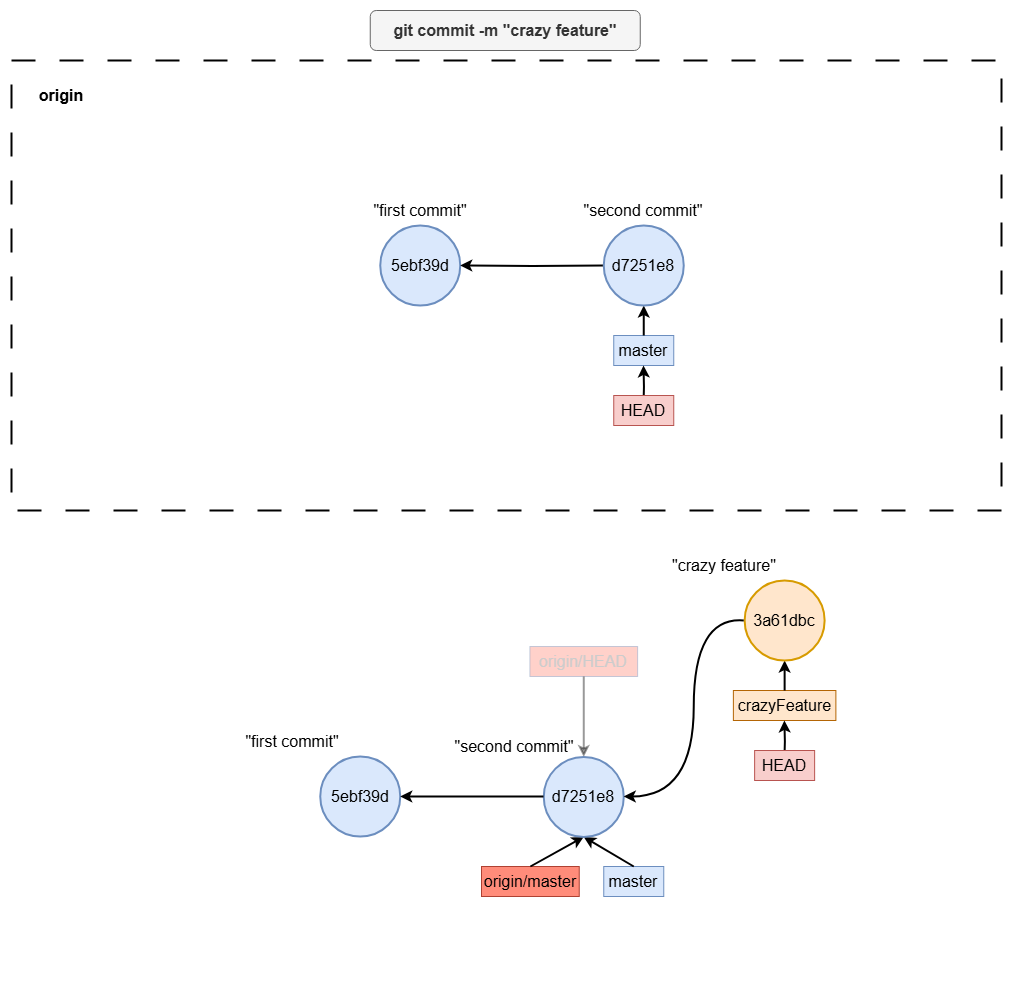
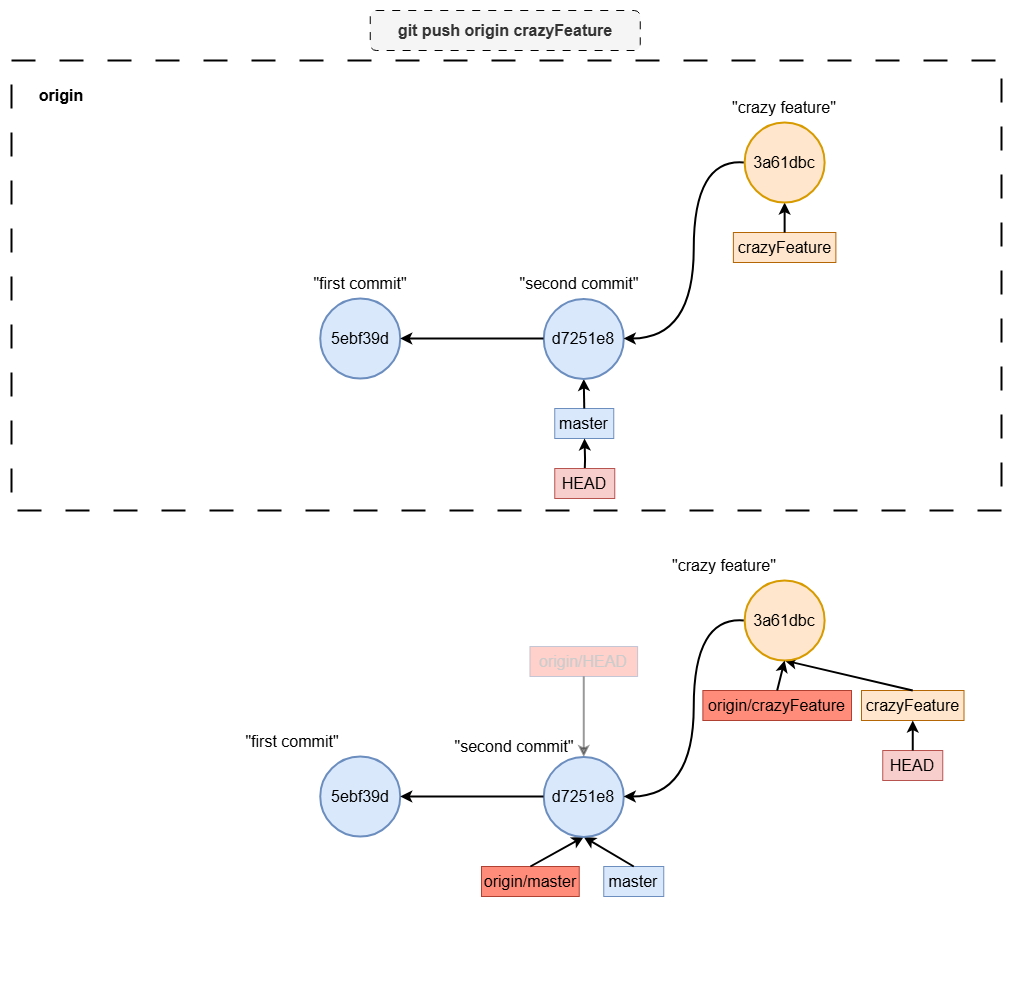
Deleting a branch
To delete a local branch reference, you can do
git push branch -d crazyFeature
To do the same thing but for a remote repository, you can do
git push -d origin crazyFeature
merging
Merging Locally
git checkout master
git merge crazyFeature
After resolving any conflicts and completing the merge locally, your local branch will contain the updated history.
Pushing the Merge to the Remote
Once the local merge is complete, you need to push the changes to the remote branch:
git push origin master
This updates the remote master branch with the result of your local merge, making it available to others.
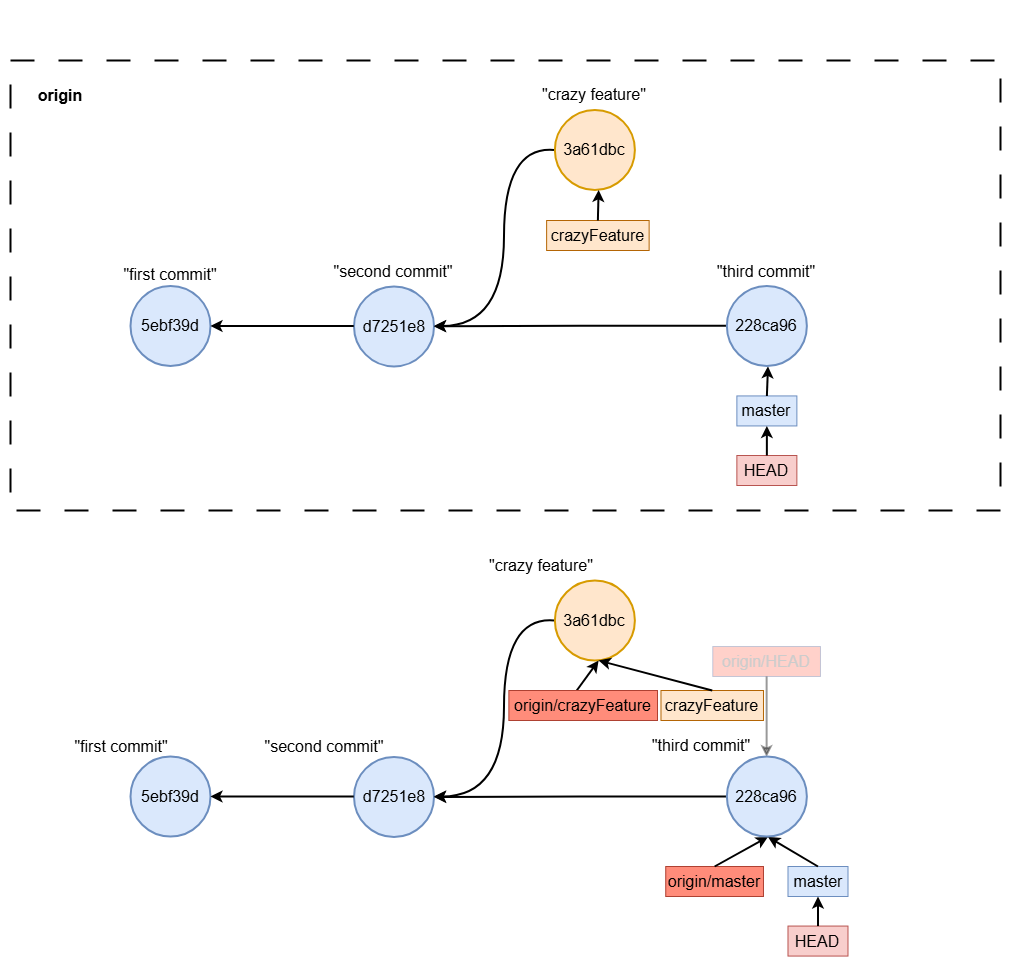
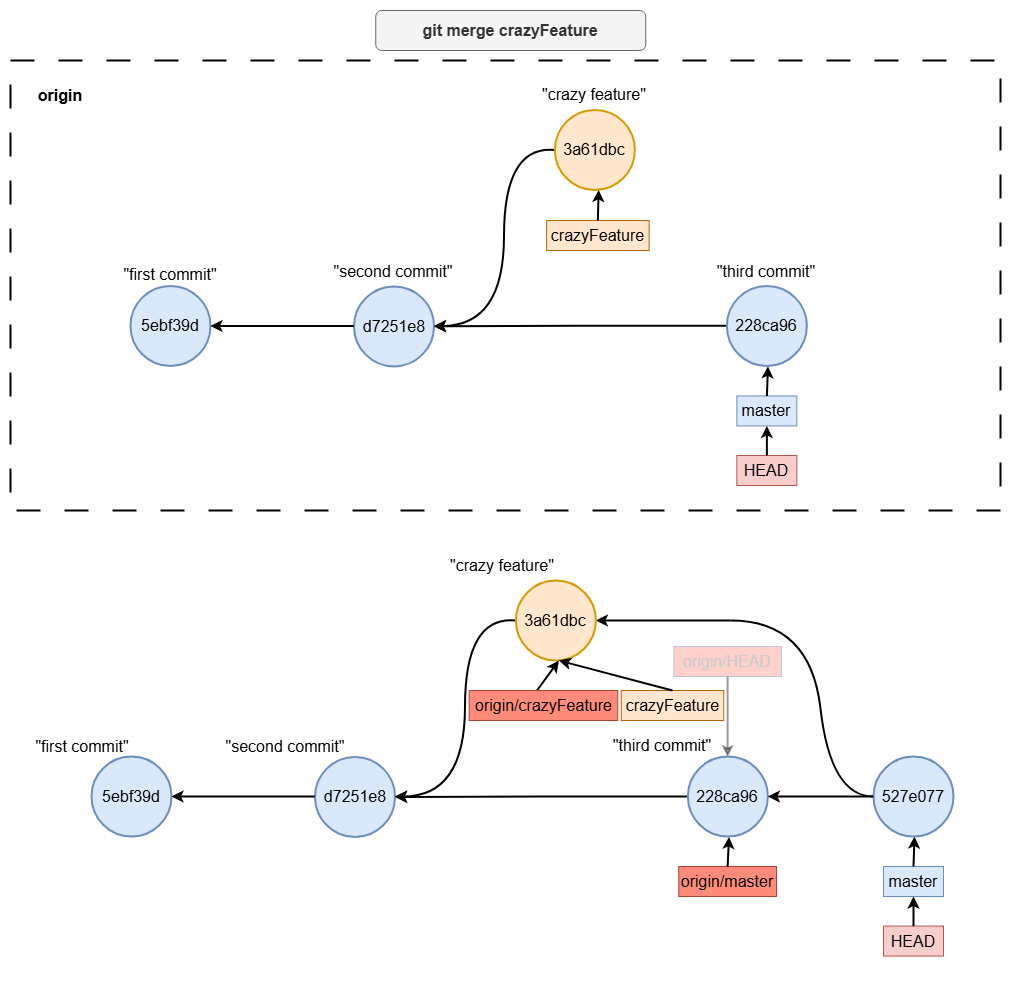
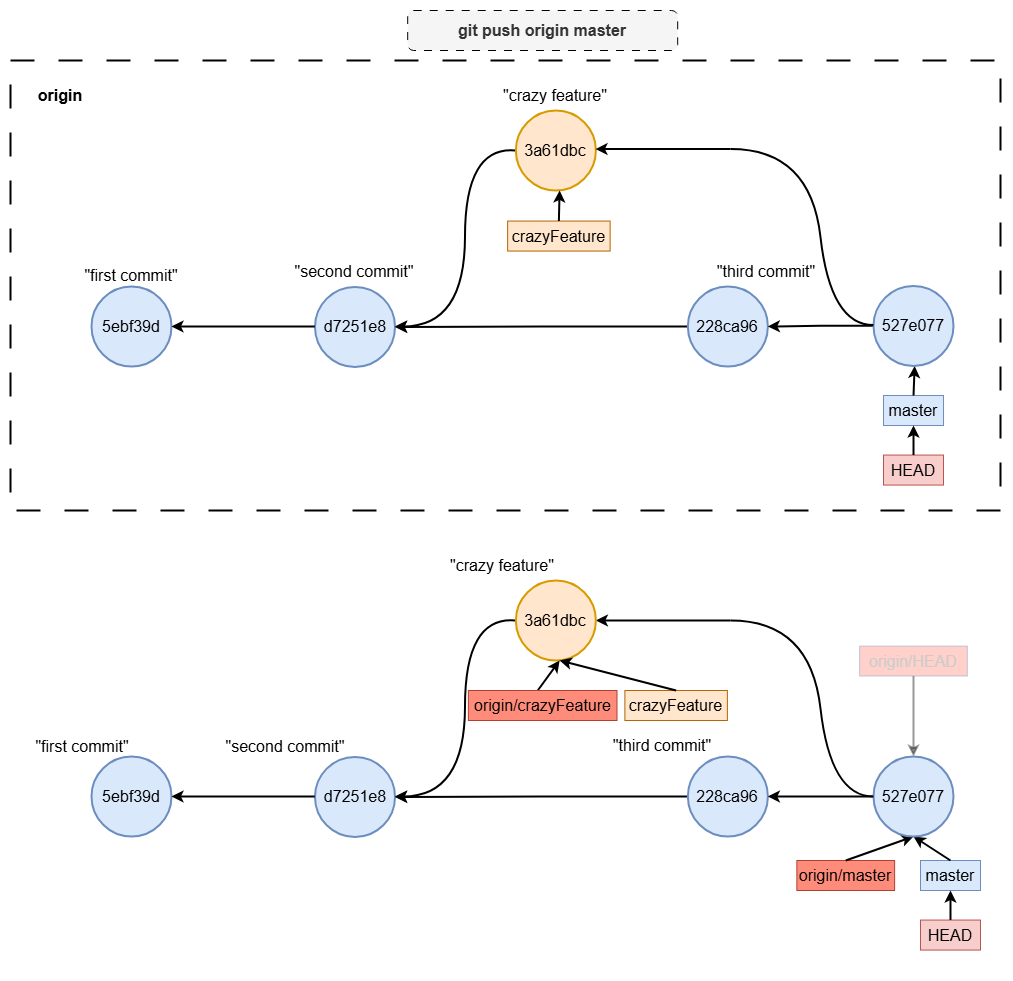
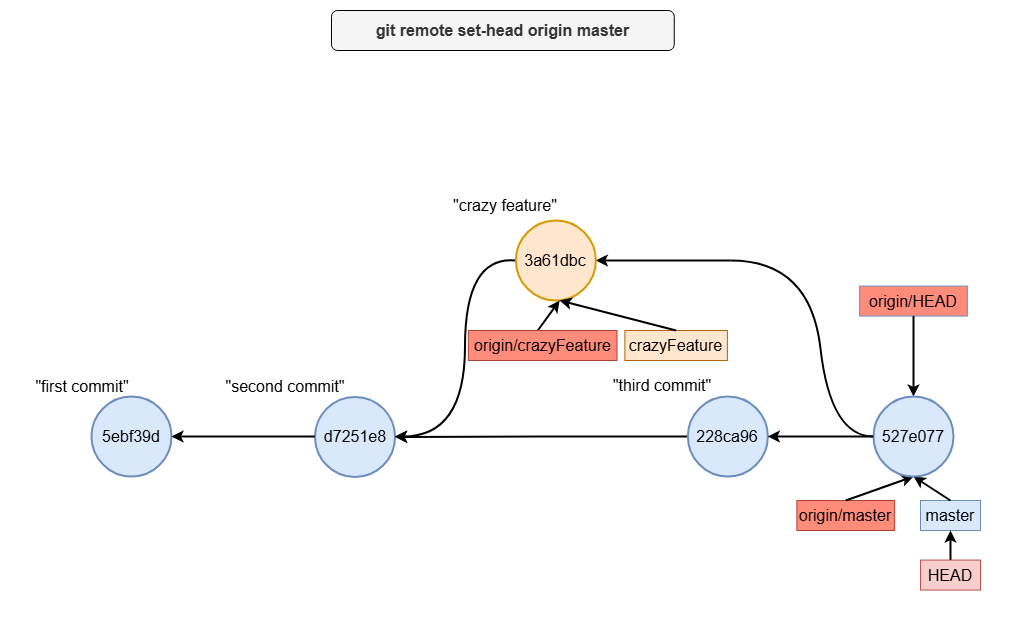
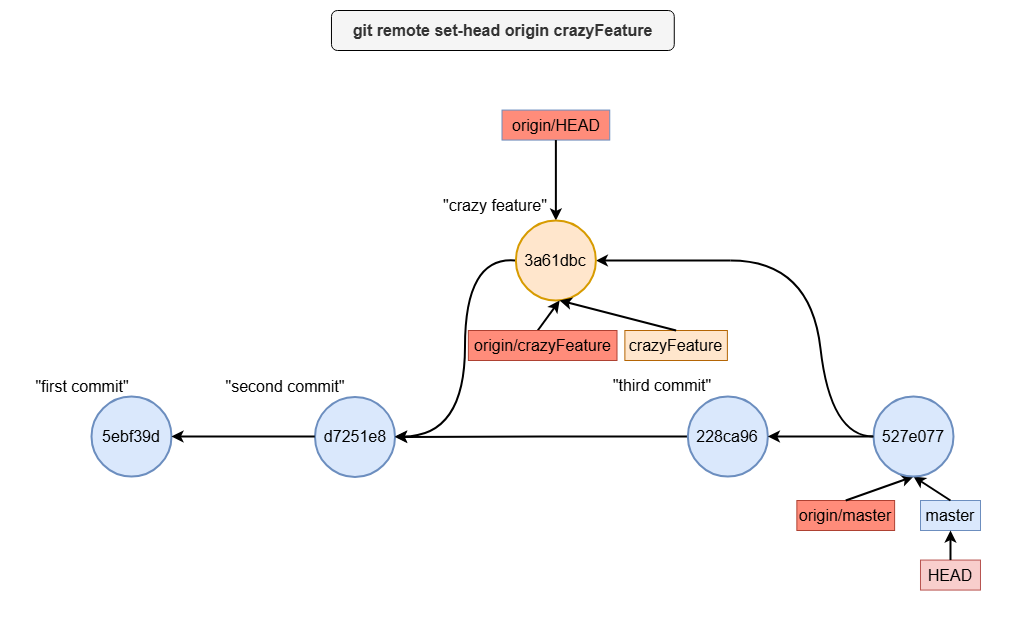
what is origin/HEAD
Setting origin/HEAD
By default, origin/HEAD points to the branch initially designated as the default branch in the remote repository. However, you can update this pointer using the git remote set-head command.
For example, if you want origin/HEAD to point to the crazyFeature branch, you can run:
git remote set-head origin crazyFeature
This makes the workflow seamless when you push changes:
git push
Git automatically knows to push to origin/crazyFeature without requiring you to specify the branch explicitly.
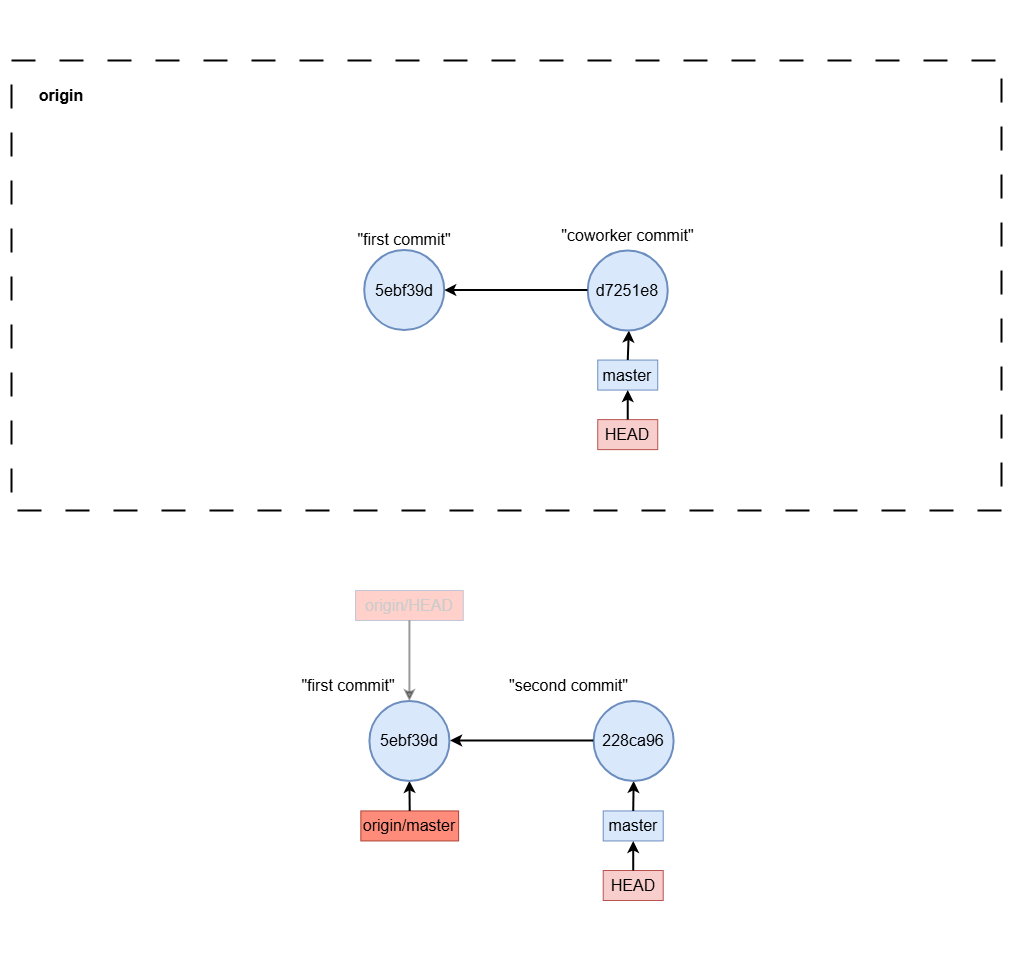
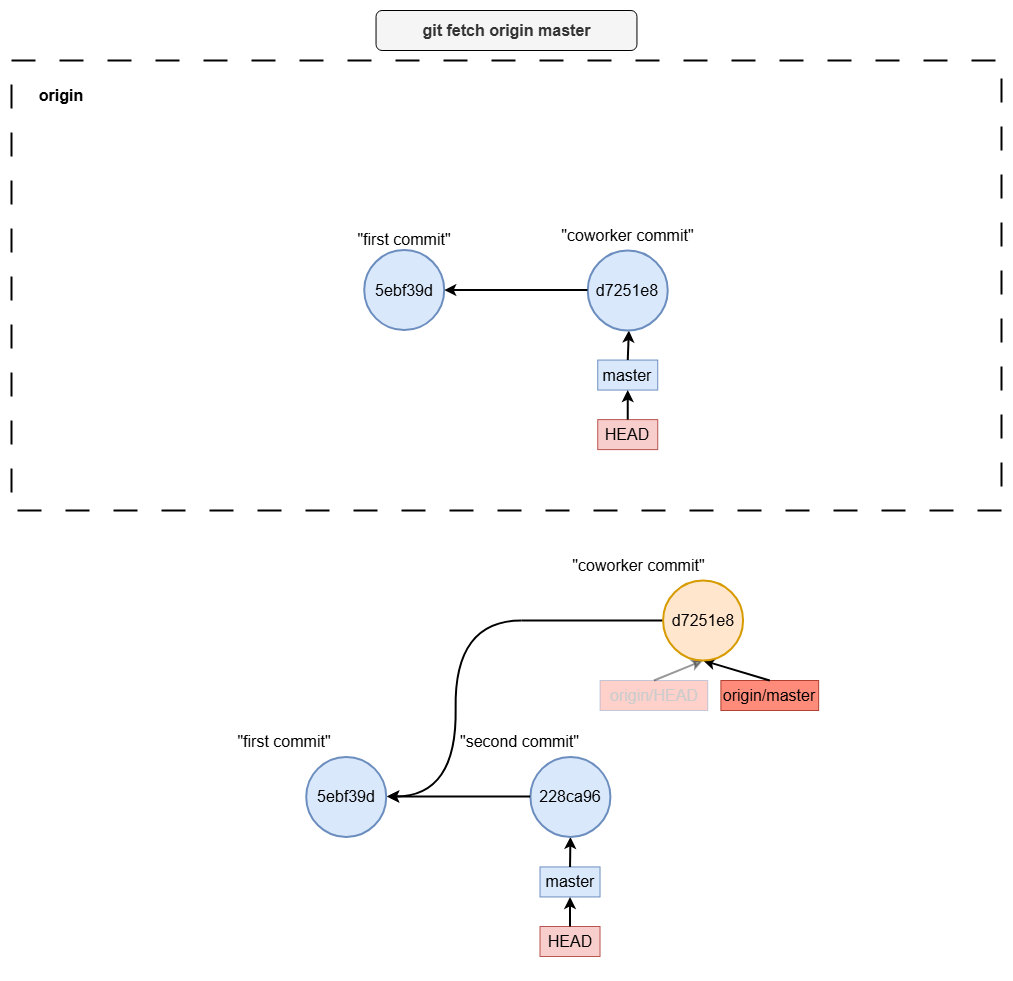
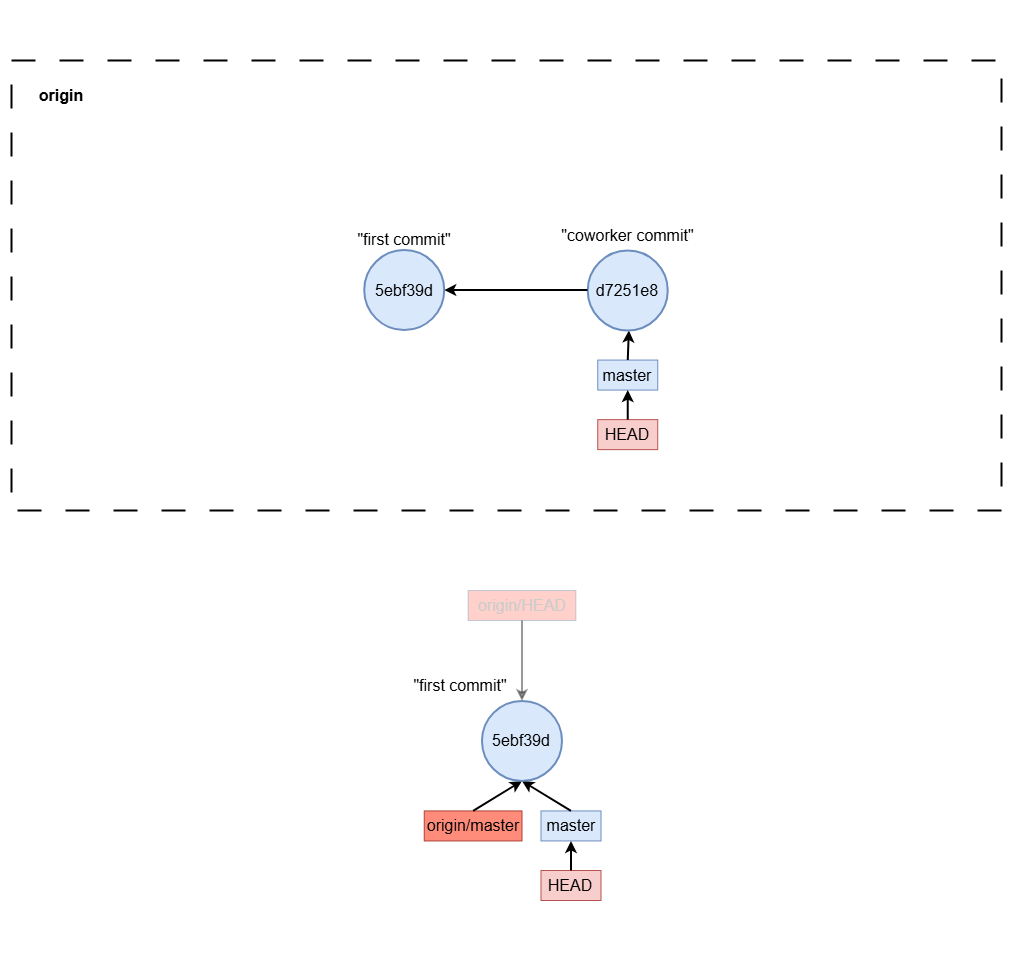
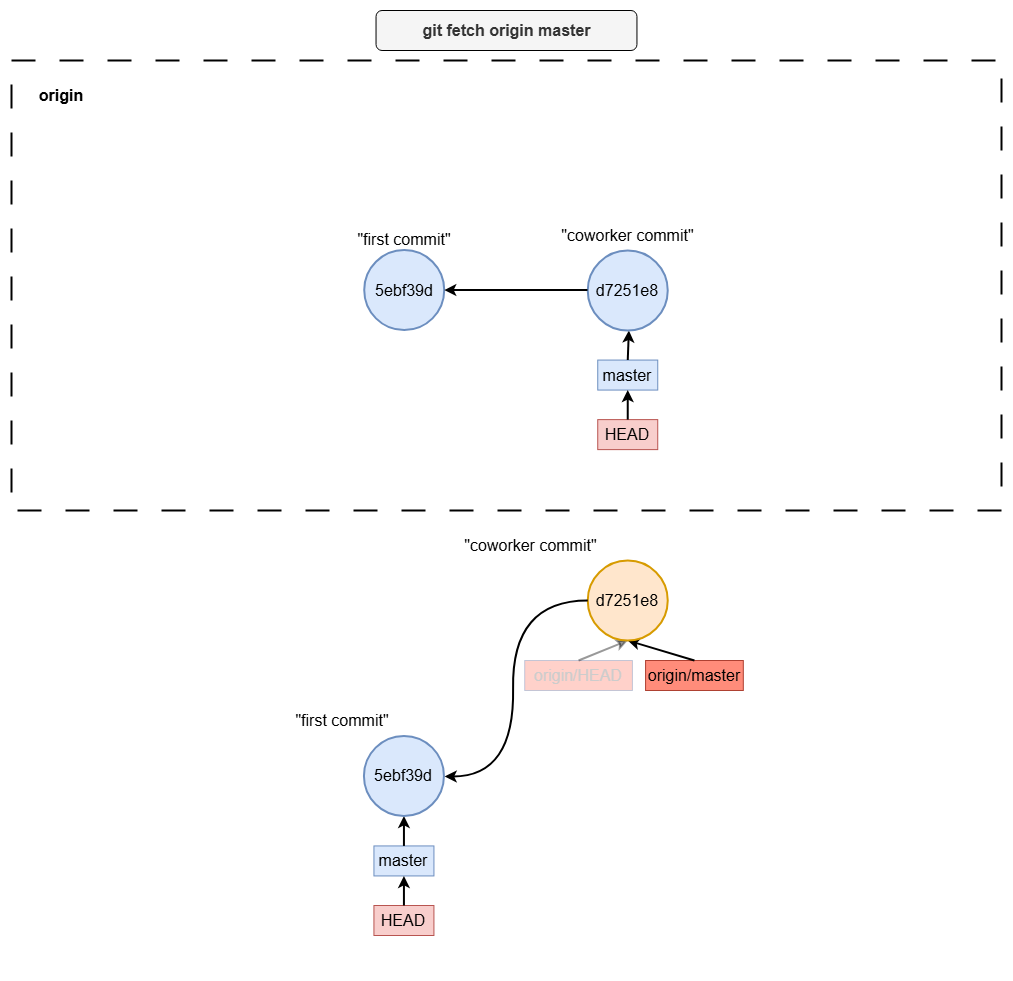
git fetch
git fetch origin master
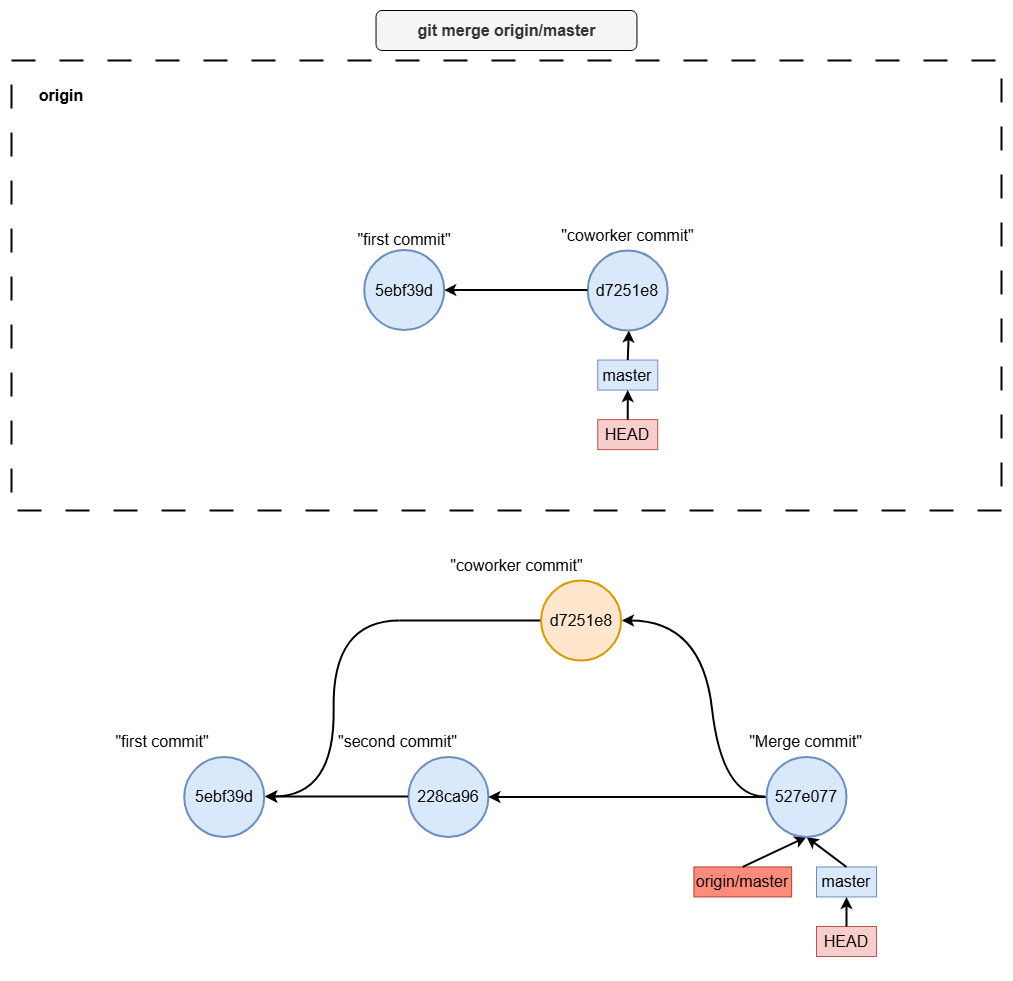
git pull
git fetchgit merge origin/<branch-name>
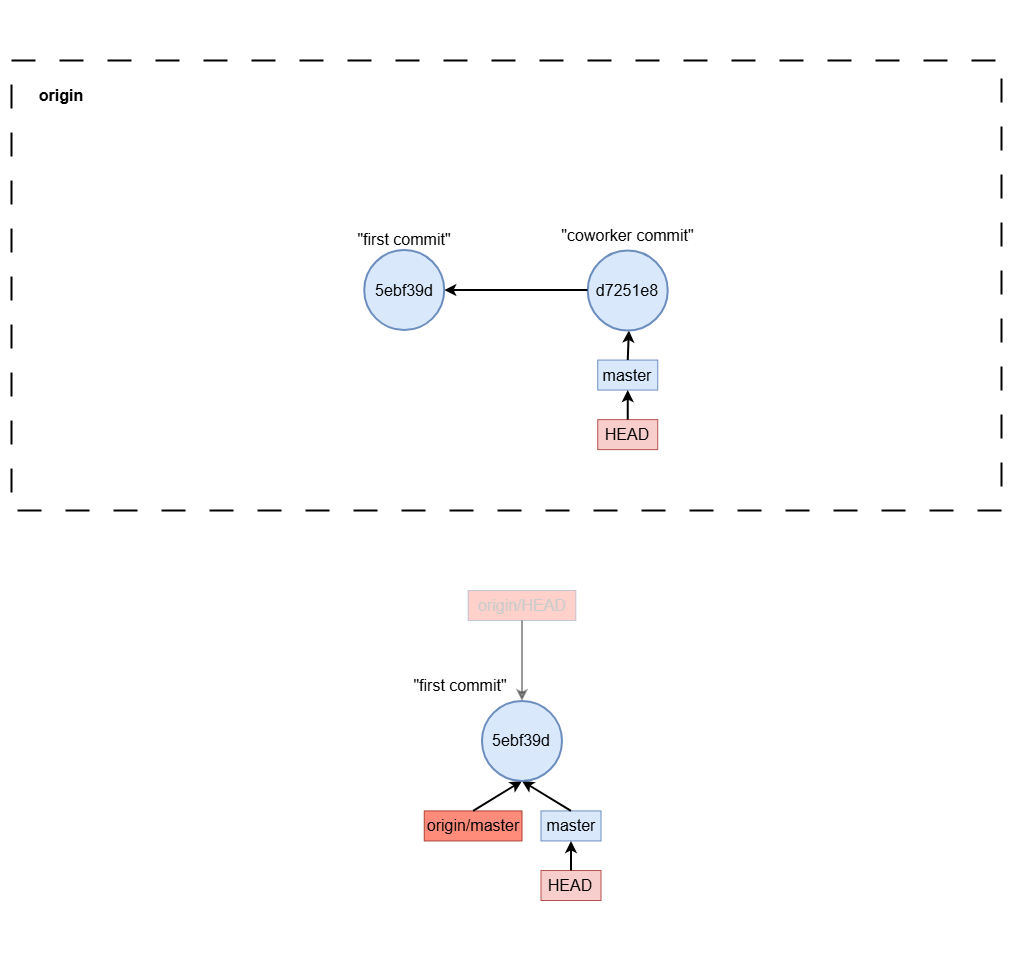
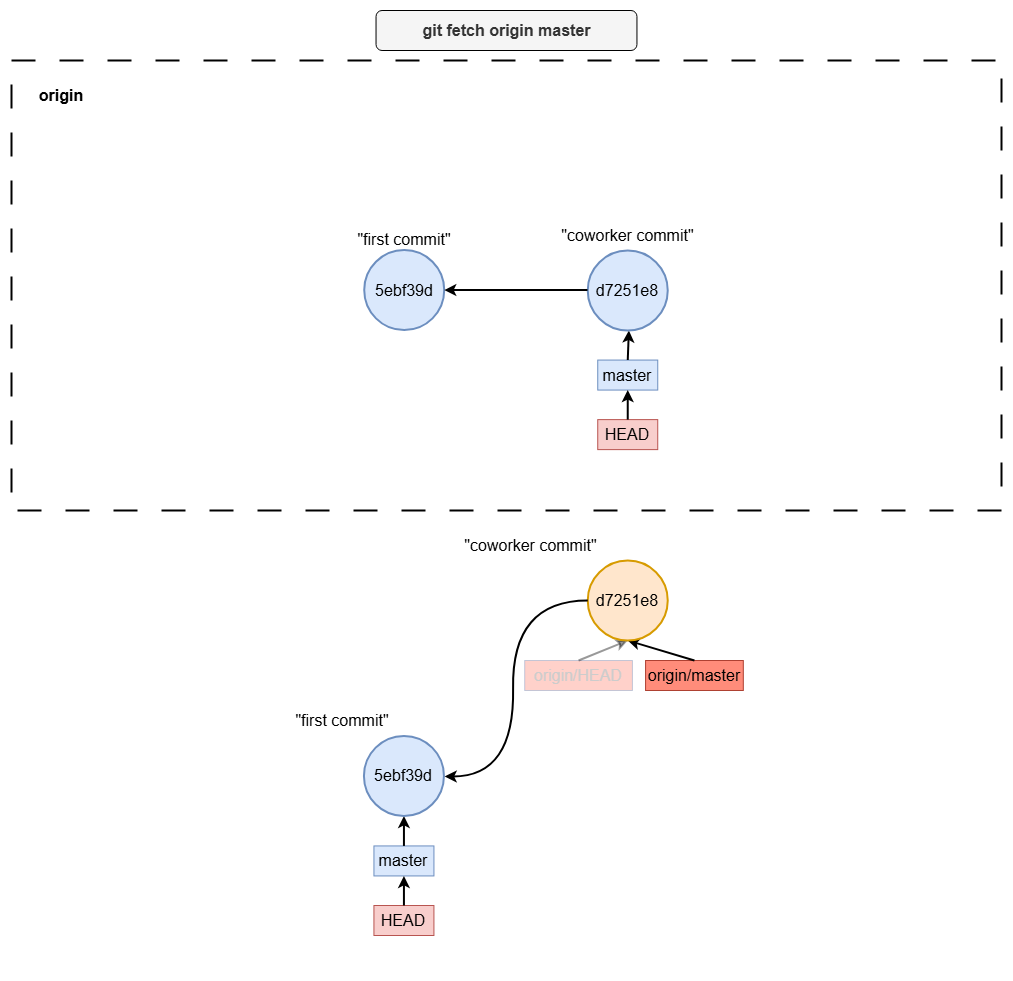
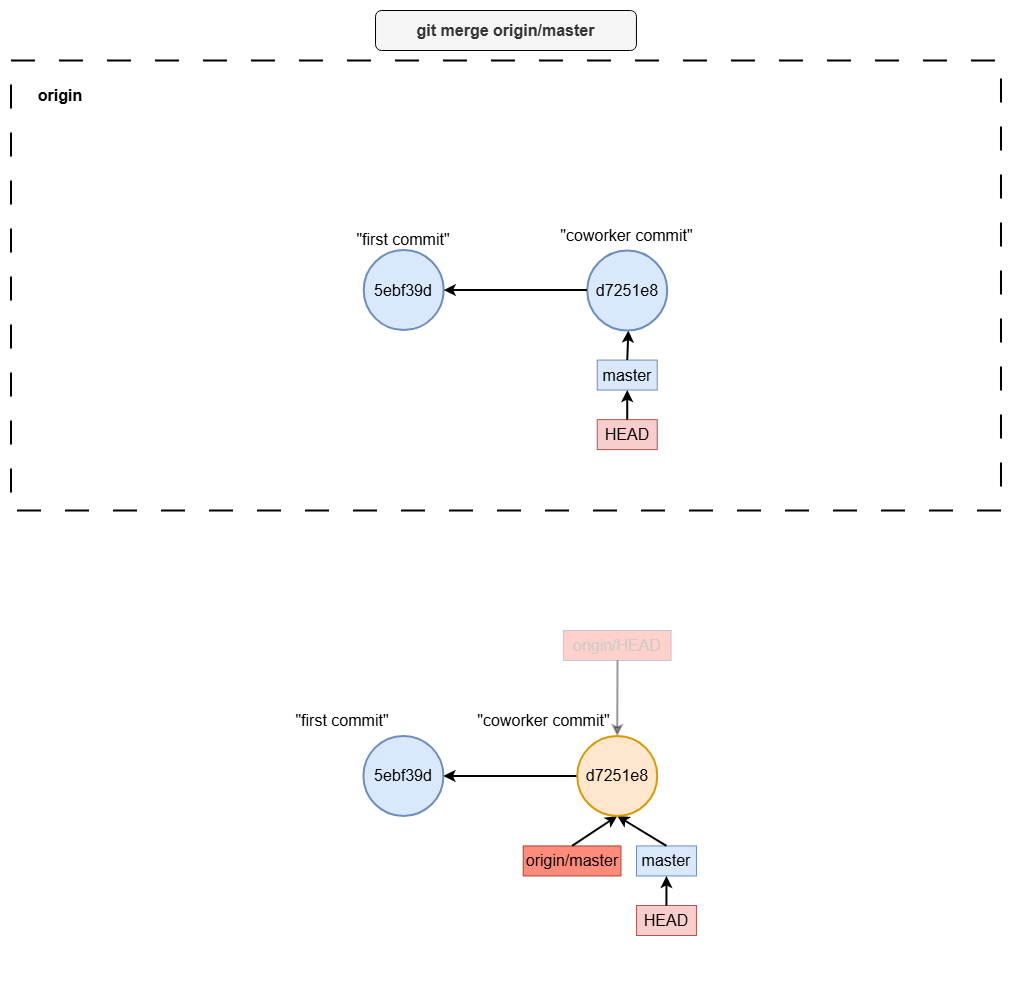
git pull common mistake